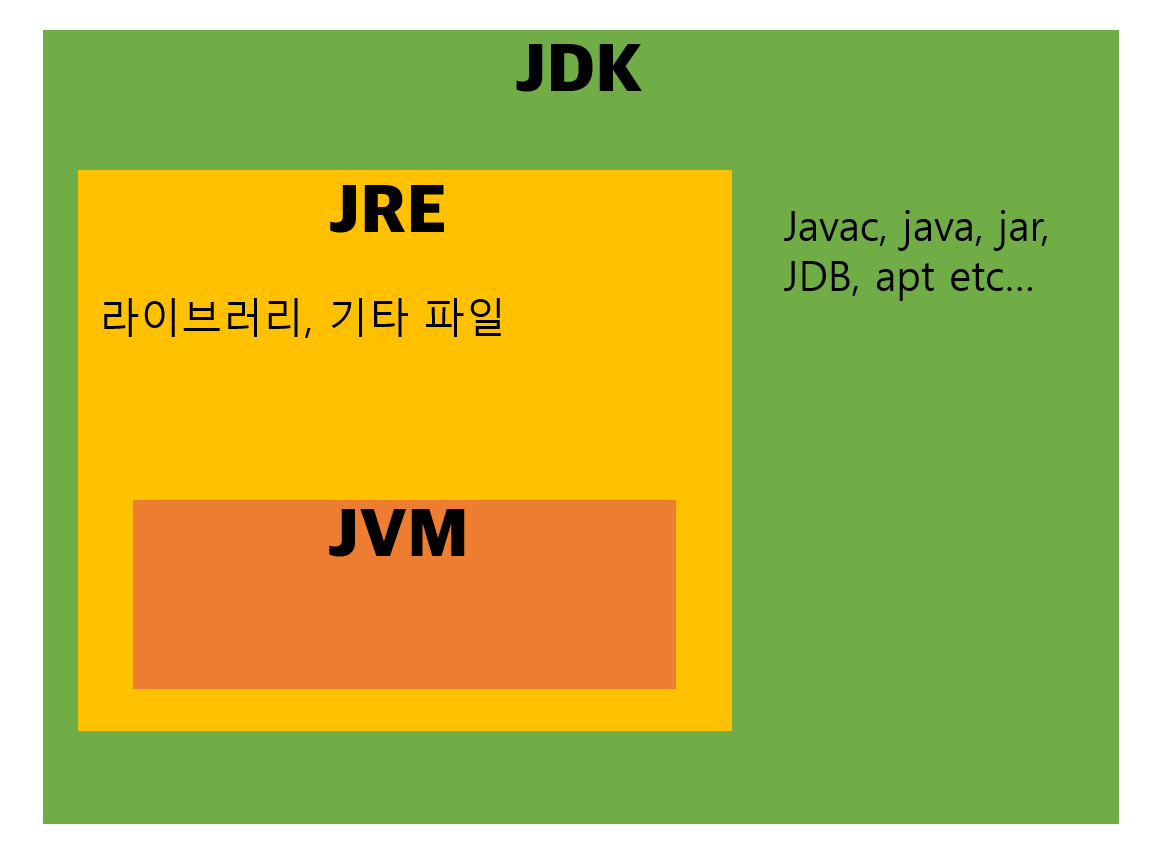
(객체지향) 캡슐화(encapsulation)란 무엇인가?
자바같은 객체지향언어를 공부하다 보면 중간중간 끊임없이 들려오는 단어가 몇 있다.
바로,
- 다형성(polymorphism)
- 추상화(abstraction)
- 캡슐화(encapsulation)
- 상속(inheritance)
이렇게 네 개의 단어와 5원칙(SOLID)이 있는데 이번 포스팅에서는 캡슐화에 대해 알아보도록 한다.
캡슐화란?
위키에는 캡슐화는 다음과 같이 서술되어 있다.
캡슐화(encapsulation)는 객체 지향 프로그래밍에서 다음 2가지 측면이 있다.
- 객체의 속성(data fields)과 행위(메서드, methods)를 하나로 묶고,
- 실제 구현 내용 일부를 내부에 감추어 은닉한다.
정의만 볼때는 뜻은 대충 알 수도 있겠지만 정확히 어디에 어떻게 사용되는 특성인지 아직 모호하다.
그렇다면 예제를 통해 이해 해 보자.
1 | public class Example { |
여기서 캡슐화는 Example 클래스 자체를 의미한다.
그렇다면 위키에서 말하는 캡슐화의 정의 중
- field와 method를 하나로 묶는지
- 구현 내용을 내부에 은닉하는지
이 두 가지를 만족하는지 한번 확인 해 보자.
Example클래스는 num 이라는 int 타입의 필드를 가지고있다.
또, getHalf 라는 메소드도 가지고 있다.
Example 클래스는 첫번째 조건에는 부합한다.
두번째 조건을 보자.
Run 클래스(외부)의 입장에서 Example 객체를 생성하고 메소드를 호출하여 사용하지만 구현이 어떻게 되어있는지 직접적으로 알지 못한다.
이렇게 두번째 조건도 만족이 된다.
이렇게 캡슐화가 무엇인지에 대해 예시를 통해 대략 알아보았다.
그렇다면 의문이 생길 수 있다.
왜 필드와 메소드를 하나로 묶는게 중요한가?
왜 그것이 외부에 노출되면 안되나?
1 | public class Example { |
이렇게 해도 결과는 동일한 10.0이 출력된다.
캡슐화를 하면 달라지는 점은 객체 내부의 데이터를 가져와서 처리하는 대신, 객체에서 처리를 한 후 결과를 가져온다.
왜 이렇게 처리 하는게 좋다는 것일까?
캡슐화의 장점을 보면 코드의 중복을 피할 수 있다는 것, 데이터를 처리하는 동작 방식을 외부에서 알 필요가 없다는 것이다.
첫번째 장점은 그렇다 쳐도 두번째 장점은 했던말을 반복하는것같다.
자 그럼 다시 예제를 통해 두 장점에 대해 알아보자
어떤 물거느이 10% 할인액을 구해야 한다고 하자, 데이터를 객체로부터 받아와서 처리를 한다면 다음과 같은 코드를 추가할 것이다.
1 | public double func(ItemData data) { |
객체로부터 가격을 가져오고 10으로 할인된 가격을 변수에 저장한 뒤 변수를 리턴해주고있다.
여기까지는 괜찮다. 그런데 이것을 다른 로직에서도 사용하게 되면 어떨까?
1 | public double func(ItemData data) { |
코드의 중복이 일어나게 되고 이같은 상황이 서비스 내에서 수십, 수백번 반복된다고 생각하면 복붙하는 행위라도 힘들것이다.
그리고 만약 이를 유지보수하는 코더가 바뀌어 10프로 할인 로직을 다음과 같이 작성할 수도 있다.
1 | public double func(ItemData data) { |
코더가 바뀌는 바람에 중복이라는 문제에 코드의 파편화라는 문제까지 끼얹어졌다.
중복이 좋지 않은건 원래도 알고있던 사실이니…. 그럼 두번째 장점인 코드의 은닉은 어떤 이점이 있을까?
위 예제에서 할인율이 20프로로 상승했다고 하자.
일단 중복된 코드가 수백개가 있다보니 수정하는 것 부터 만만치 않을것이다.
어떻게 IDE의 검색기능을 통해 수정한다고 쳐도 코더가 바뀌어 아예 검색조차 쉽지 않은경우도 많을 것이다.
그렇다고 해서 한두개의 코드라도 변경하지 못하게 될 경우 서비스에 어떤 리스크로 돌아올지 모른다.
그렇다면 이제 캡슐화를 통해 객체에서 처리를 한 후 결과를 가져오는 방식으로 해보자
1 | public class ItemData { |
이 코드에서 할인율을 20%로 증가시키는 것은 그냥 getDiscount() 메소드만 수정해주면 된다.
이처럼 캡슐화를 하니 공통된 요구사항이 변경되었을때 중복된 여러코드를 수정하는 대신 캡슐화된 클래스 하나만 변경하면 문제가 해결되었다.
Reference.
캡슐화란 무엇인가? 어떤 이점이 있는가? - bperhaps