2021 캐글 대회 코드 작성기 - 1
파이썬을 배운지 며칠 되지 않아 kaggle이라는 예측모델 및 분석대회 플랫폼의 데이터 분석 대회에 참가하게 되었다.
주제는 2021년 캐글러kaggler들에게 설문조사이며, 그 설문조사 데이터셋을 바탕으로 참가자가 분석을 하여 참가자만의 주제에 그래프와 수치로 답을 찾아내는 대회이다.
데이터셋에 있는 캐글러의 수는 19년 19717명, 21년 25974명, 직업은 데이터사이언스, 데이터 엔지니어부터 학생까지 다양하며, 나이, 학력, 국적, 라이브러리, 언어 등 매우 다양한 항목들이 있다.
우리 조에서 처음으로 선정하려 했던 주제는 한국, 일본, 중국의 캐글러의 트렌드변화로 하려 했으나, 중국, 일본에 비해 데이터가 턱없이 부족해 비교가 무의미한 수준이었기에 캐글러의 수가 비슷한 두 나라인 중국과 일본로 선정했다.(의외로 중국의 캐글러 절대적인 수가 인구에 비해 상당히 적어 일본보다 조금 적은편이였다.)
import(Kaggle notebook)
1 | import numpy as np |
이처럼 후에 사용할 라이브러리를 임포트, 그래프에 사용할 색을 리스트로 만들어주고 df19에 19년의 데이터셋을, df21에 21년의 데이터셋을 넣어준다.
사용자 지정 함수
1 | def group(data, country, question_num): |
앞으로 코드에서 사용될 함수이다.
사용자 지정 함수란?
Q1. What`s your age?
1 | JP_age_19 = group(df19,'Japan','Q1').sort_index() |

첫번째 주제인 What`s your age?에 대한 일본과 중국의 캐글러 나이분포를 막대그래프로 나타낸 것이다.
각 그래프는 연도별로 나눈 일,중 캐글러의 나이 분포이고 그래프의 항목은 18세부터 70세 이상까지 3,4년씩을 한 항목으로 묶었다.
Q2. What`s your gender?
1 | JP_ndarray = df19[df19['Q3'] == 'Japan']['Q2'].values |
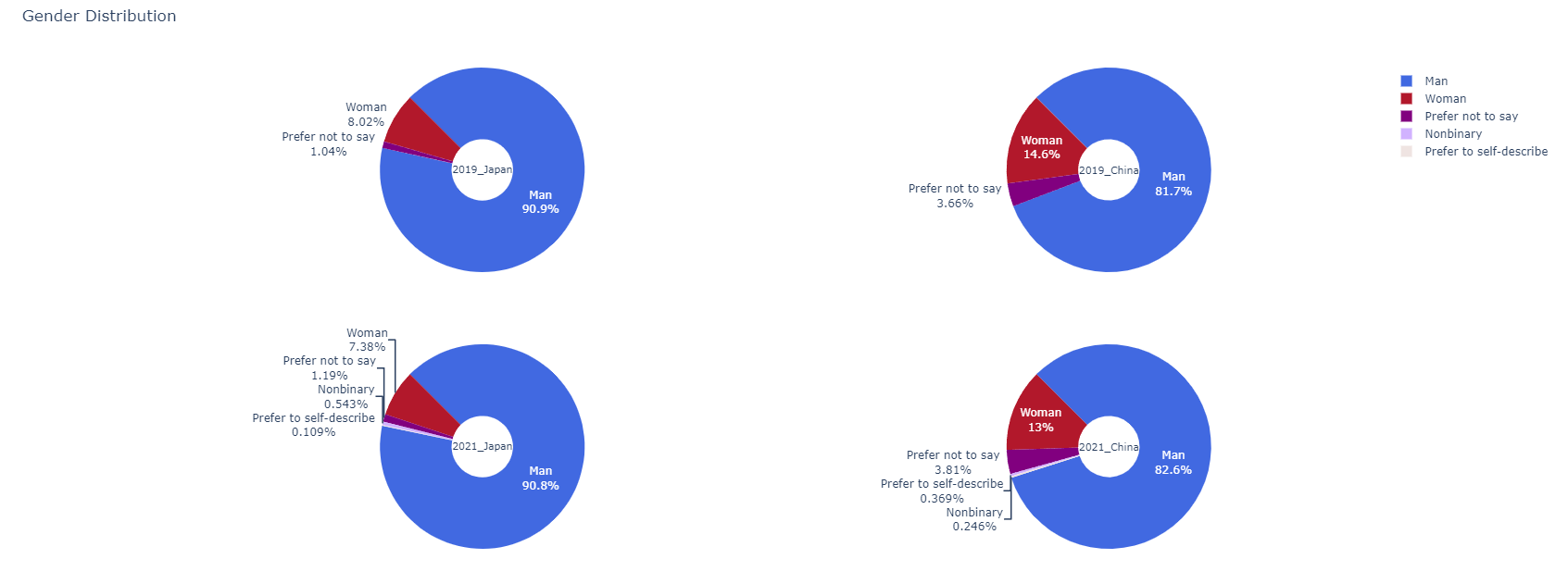
두번쨰 질문에 답하기 위해 일본과 중국의 캐글러 성별분포를 도넛모양으로 나타낸 그래프이다.
각각의 그래프는 국가,년도(2019, 2021)별로 각각 나누었고 그래프의 항목은ManWomanPrefer not to sayNonbinaryPrefer to self-describe
이렇게 다섯가지로 나누었다.
References
plotly bar chart tutorial
plotly bar chart properties (bar traces)
plotly pie chart tutorial
plotly pie chart properties (pie traces)
2021 캐글 대회 코드 작성기 - 1
https://cincu4221.github.io/2021/11/17/kaggle-2021survey-code-1/
install_url to use ShareThis. Please set it in _config.yml.