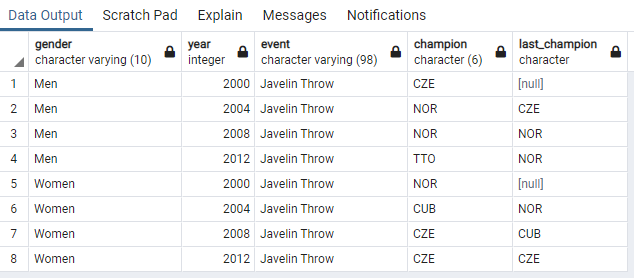
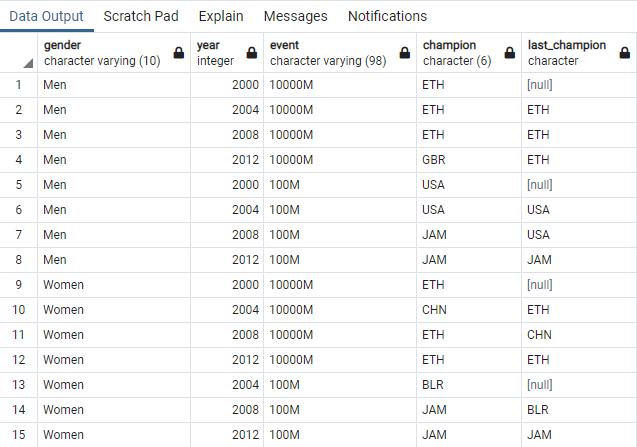
WITH Athletics_Gold AS ( -- 이하 서브쿼리의 이름 SELECT gender -- 성별, 연도, 종목, 국가(as champion) 조회 , year , event , country AS champion FROM summer_medals -- 조회 테이블 WHERE YearIN (2000, 2004, 2008, 2012) -- year컬럼이 2000, 2004, 2008, 2012 중에 하나이며 AND Medal ='Gold'-- medal컬럼은 Gold AND Event IN ('100M', '10000M')) -- 100M 또는 10000M 종목인것 SELECT gender -- 성별, 연도, 종목, 현재 1위국가 , year , event , champion, LAG(Champion) OVER (PARTITIONBY gender, event ORDERBYYearASC) AS-- 파티션을 gender와 event로 분류하고 year의 오름차순으로 정렬 Last_Champion -- as Last_Champion FROM Athletics_Gold -- 위 쿼리에서 생성한 Athletics_Gold 테이블에서 조회 ORDERBY gender asc, event ASC, yearASC; -- gender, event, year의 순서대로 오름차순 정렬
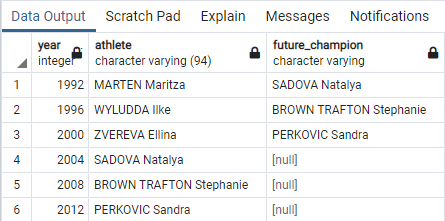
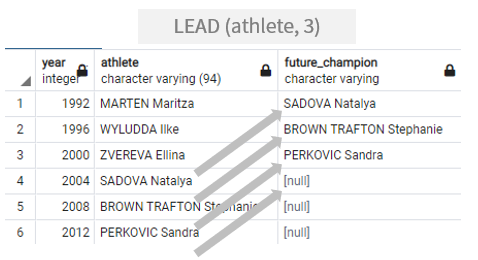
-- year, athlete, future_champion(3회 이후 챔피언) -- 조건 : Medal =Gold / event = discus Throw / gender women / year >= 1992 -- lead(컬럼명, 3) over() WITH DiscusThrow_Gold AS ( -- 이하 서브쿼리의 이름 select year-- 연도, 선수 조회 , athlete from summer_medals -- 조회 테이블 where medal ='Gold'-- 조건들 : medal컬럼이 Gold이며, and event ='Discus Throw'-- event컬럼이 Discus Throw, and gender ='Women'-- gender컬럼이 Women, andyear>=1992-- year컬럼이 1992 년 이후인것 )
select year-- 연도, 선수, future_champion , athlete , lead(athlete, 3) over-- lead(컬럼, 숫자(기본값1)) = 괄호안의 컬럼의 이후값(숫자만큼)을 건너뛰고 가져와 컬럼을 새로 만듦 () as future_champion -- as future_champion from DiscusThrow_Gold; -- DiscusThrow_Gold 테이블에서 조회
이전까지 쿼리에서 사용된 LAG함수와 LEAD함수는 다음 절에서 설명한다.
LAG() 함수와 LEAD() 함수
LAG() 함수
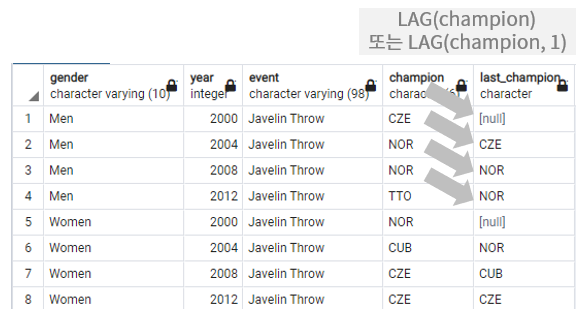
LAG함수는 보통 LAG(column, n(기본값1))의 형태인데 이는 현재 행 앞의 행에 있는 열의 값을 반환한다.
그렇기 때문에 위 사진에서 last_champion의 첫번째 결과는 null이 된다(앞의 결과가 없기때문)
이후 부터는 champion컬럼의 결과가 차례로 출력된다.
참고로 5번 열에서의 null은 gender를 partition by로 나누었고 현재 행의 앞의 열을 분리시킨상태이기 때문에 null값이 조회된다.
LEAD() 함수
기본적인형태는 LEAD(column, n(기본값1))의 형태이며,
LEAD 함수는 LAG 함수와는 반대로 현재 행 뒤의 행에 있는 열의 값을 반환한다.
사진에서 사용한 코드는 LEAD(athlete,3) 이므로 3칸 뒤의 열의 값을 반환한다.
이후 athlete컬럼의 결과가 차례로 출력되며 3번열 이후의 값은 존재하지 않기때문에 null이 반환된다.
-- row_number() -- 각 행에 숫자를 1, 2, 3, ..., N 형태로 추가한다. -- 오름차순으로 기준을 진행한다. -- 기본적 row_num만 추가 select row_number() over() as row_num , * from summer_medals;
-- 올림픽 연도를 오름차순 순번대로 작성을 한다. -- 연도 중복값 제거 -- 서브쿼리 : select distinct year from summer_medals order by year asc; select row_number() over() as row_num -- 각 행에 오름차순으로 숫자 추가 as row_num, year행 출력 , year from (selectdistinctyearfrom summer_medals orderbyyearasc) as years -- 중복값을 제거한 year 컬럼을 오름차순으로 출력 as years orderbyyearasc; -- select절의 컬럼들을 year컬럼의 오름차순으로 정렬
select*from summer_medals;
-- 운동선수 메달 갯수 쿼리 작성 with athlete_medals as ( select athlete -- athlete, 전체 컬럼을 count하고 athlete로 묶음(group by절) as medal_counts , count(*) medal_counts from summer_medals groupby athlete ) select athlete -- athlete, medal_counts, medal_counts의 내림차순으로 숫자를 붙인 row_num 출력 , medal_counts , row_number() over(orderby medal_counts desc) as row_num from athlete_medals orderby medal_counts desc-- select절의 컬럼들을 medal_counts의 내림차순으로 정렬 limit 10; -- 상위 10개만 출력
-- 남자 69 KG 역도 경기에서 금메달 리스트 추출. -- Discipline = 'Weightlifting' -- Event 69KG, -- Gender -- Medal select*from summer_medals; selectdistinct event, discipline, athlete, gender from summer_medals where event ='200M'and gender ='Women'and medal ='gold';
select year-- 연도, 국가 as champion 출력 , country as champion from summer_medals where discipline ='Weightlifting'and-- 종목 = 역도, event ='69KG'and-- 세부종목 = 69KG, gender ='Men'and-- 성별 = 남자, medal ='Gold'; -- 금메달만, 상기 4개 조건 모두 만족하는결과만 출력
-- LAG
with weightligting_69_men_gold as ( select year , country as champion from summer_medals where discipline ='Weightlifting'and event ='69KG'and gender ='Men'and medal ='Gold' )
select year , champion , LAG(champion) over(orderbyyearasc) as last_champion from weightligting_69_men_gold orderbyyearasc;
-- Athletics, 200미터, 여자, 금메달 목록 가져오기 -- 나라 대신 선수이름 출력 year, 현재 챔피언 이름, 이전 챔피언 이름
with Athletics_200_Women_Gold as ( select year , athlete as champion from summer_medals where discipline ='Athletics'and event ='200M'and gender ='Women'and medal ='Gold' )
select year , champion , lag(champion) over(orderbyyearasc) as last_champion from Athletics_200_Women_Gold orderbyyearasc;
-- partition by 함수 -- partition by 미적용 WITH Discus_Gold_Medal AS ( SELECT Year, Event, Country AS Champion FROM summer_medals WHERE YearIN (2004, 2008, 2012) AND Gender ='Men'AND Medal ='Gold' AND Event IN ('Discus Throw', 'Triple Jump') AND Gender ='Men') SELECT YEAR, Event, Champion, LAG(Champion) OVER (ORDERBY Event ASC, YearASC) AS Last_Champion FROM Discus_Gold_Medal ORDERBY Event ASC, YearASC;
-- partition by 적용 WITH Discus_Gold_Medal AS ( SELECT Year, Event, Country AS Champion FROM summer_medals WHERE YearIN (2004, 2008, 2012) AND Gender ='Men'AND Medal ='Gold' AND Event IN ('Discus Throw', 'Triple Jump') AND Gender ='Men') SELECT YEAR, Event, Champion, LAG(Champion) OVER (PARTITIONBY Event ORDERBY Event ASC, YearASC) AS Last_Champion FROM Discus_Gold_Medal ORDERBY Event ASC, YearASC;
-- 서브쿼리 쓰는 방식 -- where 절 서브쿼리 -- select 절 서브쿼리 -- from 절 서브쿼리
select*from languages; select*from countries;
-- 질문 : 각 나라별 언어의 갯수 구하기 -- Table: languages select code, count(*) as lang_num -- 국가 코드, 모든행을 카운트해 lang_num 으로 출력 from languages -- 사용한 테이블 groupby code; -- 국가 코드로 묶을것 -- 결과 : 각각의 국가 코드로 묶인 lang_num 출력
-- 질문, country로 변경하고, 언어의 갯수 구하기 -- lang_num을 내림차순으로 정렬함. -- 이 쿼리서 from절 서브쿼리 사용 select local_name, subquery.lang_num -- countries 테이블의 local_name, (as)subquery 에서 lang_num을 각각 출력 from countries -- 테이블은 countries 와 다음의 서브쿼리 , (select code, count(*) as lang_num -- 전 질문의 쿼리를 가져와 'subquery' 명칭을 붙임 from languages groupby code) as subquery where countries.code = subquery.code -- countries.code 와 subquery.code가 매칭이 될 경우만 조회 orderby lang_num desc; -- lang_num을 내림차순으로 정렬 -- 결과 : countries.local_name과 subquery.lang_num이 각각 lang_num의 내림차순으로 출력
-- select*from economies whereyear=2015;
-- 코드별 inflation_rate -- 각 대륙별, 각 나라별 inflation_rate -- 각 대륙에서 inflation_rate가 가장 높은, inflation_rate를 출력
SELECT name, continent, inflation_rate -- name, continet, inflation_rate 를 조회 FROM countries -- countries 테이블 INNERJOIN economies -- inner join = 기준테이블, 조인테이블 모두에 해당 값이 존재할 경우 메인쿼리 조회 on countries.code = economies.code -- economies 와 countries.code = economies.code 에 겹치는 값이 있는지 WHEREyear=2015-- year항목이 2015이고 and inflation_rate in ( -- inflation_rate 항목에 다음 서브쿼리의 값이 있는지 SELECTMAX(inflation_rate) AS max_inf -- 가장 큰 inflation_rate를 조회 FROM ( -- 다음의 서브쿼리에서 SELECT name, continent, inflation_rate -- name, continent, inflation_rate 조회 FROM countries -- countries 테이블 INNERJOIN economies -- economies 와 on countries.code = economies.code -- countries.code = economies.code 에 겹치는 값이 있는지 WHEREyear=2015) AS subquery -- year = 2015인 것만 조회 ) subquery로 명명 GROUPBY continent); -- 바로 위에서 출력한 서브쿼리를 continent로 묶음 -- 결과 : countries테이블의 name, continent, inflation_rate 조회 group by 때문에 대륙별로 한 나라씩만 조회되었고 조회된 나라의 기준은 inflation_rate가 가장 높은 국가
첫번째와 두번째 쿼리는 직접 작성하지는 못해도 해석은 할 수 있었는데 마지막 쿼리는 정말이지 복잡했다. 강의 뿐만 아니라 책도 구매해서 SQL를 더 파야 할 듯.
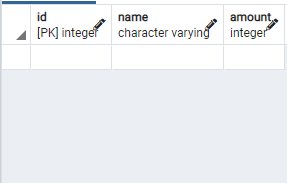
--실제 보유하고 있는 과일 데이터 select*from real_amount; -- 테이블값 있음, 위 이미지 첫번째 테이블
-- 카운터 컴퓨터에서 추정한 과일 데이터 select*from assumption_amount; -- 테이블값 있음, 두번째 테이블
-- 외상 데이터 select*from exception; -- 테이블값 없음, 세번째
-- 기본적으로 서브쿼리에서 true가 반환되어야 메인쿼리가 실행되는듯 -- exists(서브쿼리) == 서브쿼리의 결과가 한건이라도 존재할 경우 True 없으면 False 리턴 -- 카운터에는 데이터 존재 / 외상 데이터 현재 없음 select*from real_amount -- 현재 과일 데이터 출력 whereexists ( -- 위의 exists 설명 참조 select*from assumption_amount -- 컴퓨터 추정 과일데이터 ); -- 결과 : 컴퓨터에서 추정한 과일 데이터가 존재하니 exists == true 반환, 그러므로 메인쿼리가 실행됨
select*from real_amount -- 현재 과일 데이터 출력 whereexists ( -- 위의 exists 설명 참조 select*from exception -- 외상데이터 ); -- 결과 : 외상데이터 조회시 테이블값이 없기 때문에 exists == false 반환, 메인쿼리가 실행되지 않음 -- SQL의 아웃풋 창에는 select * from exception이 출력
-- IN 연산자 / NOT IN 연산자 -- IN 연산자 : 하나이상의 값이 도출이 되면 true select*from real_amount -- 현재 과일 데이터 출력 where amount in ( -- amount(메인쿼리의 테이블에서 값을 받아오는 것으로 추정)값에 10, 20, 30 이 있을경우 true 10, 20, 30 ); -- 결과 : real_amount 테이블의 amount 컬럼에 10과 30이 존재하기 때문에 메인쿼리가 실행되어 현재 과일데이터가 출력됨
-- ANY 연산자 select*from real_amount -- 현재 과일 데이터 출력 (3) where10=any ( -- 서브쿼리의 출력에 10이 있을 경우 (2) select amount from assumption_amount -- assumption_amount 테이블의 amount 컬럼을 출력 (1) ); -- 결과 : assumption_amount 테이블의 amount 컬럼에 10이 존재하기 때문에 real_amount 출력
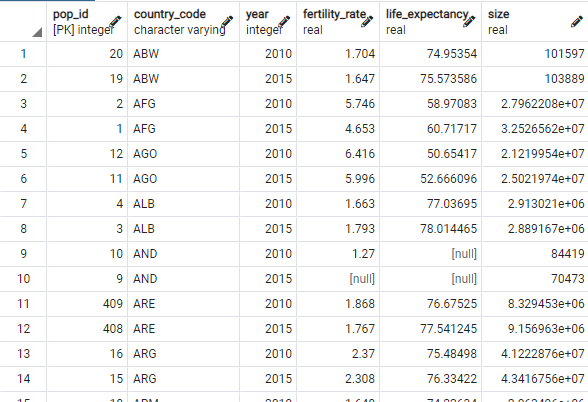
selectavg(life_expectancy) from populations; -- 모든 life_expectancy의 평균값 출력
-- count(*) 입력한 행의 총 갯수 selectcount(*) from populations; -- populations 테이블의 모든 행 갯수 - 434
-- count(컬럼명) NULL 값이 아닌 해당 컬럼 행의 갯수 selectcount(life_expectancy) from populations; -- populations 테이블의 NULL이 있는 행을 제외한 life_expectancy 컬럼의 갯수 - 398
-- max, min, sum -- 모두NULL 값이 아닌 해당 컬럼 행만 계산 selectmax(life_expectancy) from populations;
selectmin(life_expectancy) from populations;
selectsum(life_expectancy) from populations;
-- 기대수명이 가장 높은 country code select country_code, life_expectancy -- country_code, life_expectancy 출력 (5) from populations -- populations 테이블의(4) where life_expectancy = ( -- (2)와 동일한 life_expectancy값을 가진 행의 (3) selectmin(life_expectancy) -- life_expectancy컬럼의 최솟값(2) from populations -- populations 테이블의 (1) ); -- 결과 : populations 테이블의 life_expectancy컬럼의 최소값과 동일한 life_expectancy를 가진 country_code, life_expectancy를 populations 테이블에서 찾아 출력
-- 삼중쿼리 -- 집계함수는 where절에서 사용 불가이기 때문에 서브쿼리 사용 select country_code -- country_code 출력 (8) from populations -- populations테이블의 (7) where code = ( -- (5)에서 선택된 테이블의 행중에 code 컬럼과 같은값을 가진 행 (6) select*-- (4)에서 선택된 테이블의 모든 컬럼 조회 (5) from countries -- countries 테이블 (4) where life_expectancy = ( -- (2)와 동일한 life_expectancy값을 가진 행 (3) selectmin(life_expectancy) -- life_expectancy컬럼의 최솟값 (2) from populations -- populations 테이블의 (1) )); -- 복잡하다... 설명을 못해서 그렇기도 하지만, 차라리 SQL로 보는게 낫지 한글로 풀어설명하는게 더 복잡하다.
-- 조건 1. 2015년 전체 국가의 평균 수명 계산 -- 조건 2. 모든 데이터를 조회합니다. -- 조건 3. 2015년 평균 기대수명의 1.15배보다 높도록 조건을 설정합니다.
-- 이번엔 거꾸로 과정 작성 select*-- 모든 컬럼 출력 (1) from populations -- populations 테이블의 (2) where life_expectancy >1.15* ( -- 단, life_expectancy가 서브쿼리 값의 1.15배보다 큰것만 출력 (3) selectavg(life_expectancy) -- life_expectancy의 평균값 출력(4) from populations -- populations 테이블의 (5) whereyear=2015) -- year 컬럼이 2015인것들로만 평균값 출력(6) andyear=2015; -- (3)의 and조건 추가절, year가 2015 일것. -- 결론 : 2015년도의 평균life_expectancy * 1.15 보다 크고, year 가 2015인 행의 모든 컬럼 출력 -- 간단한 편..
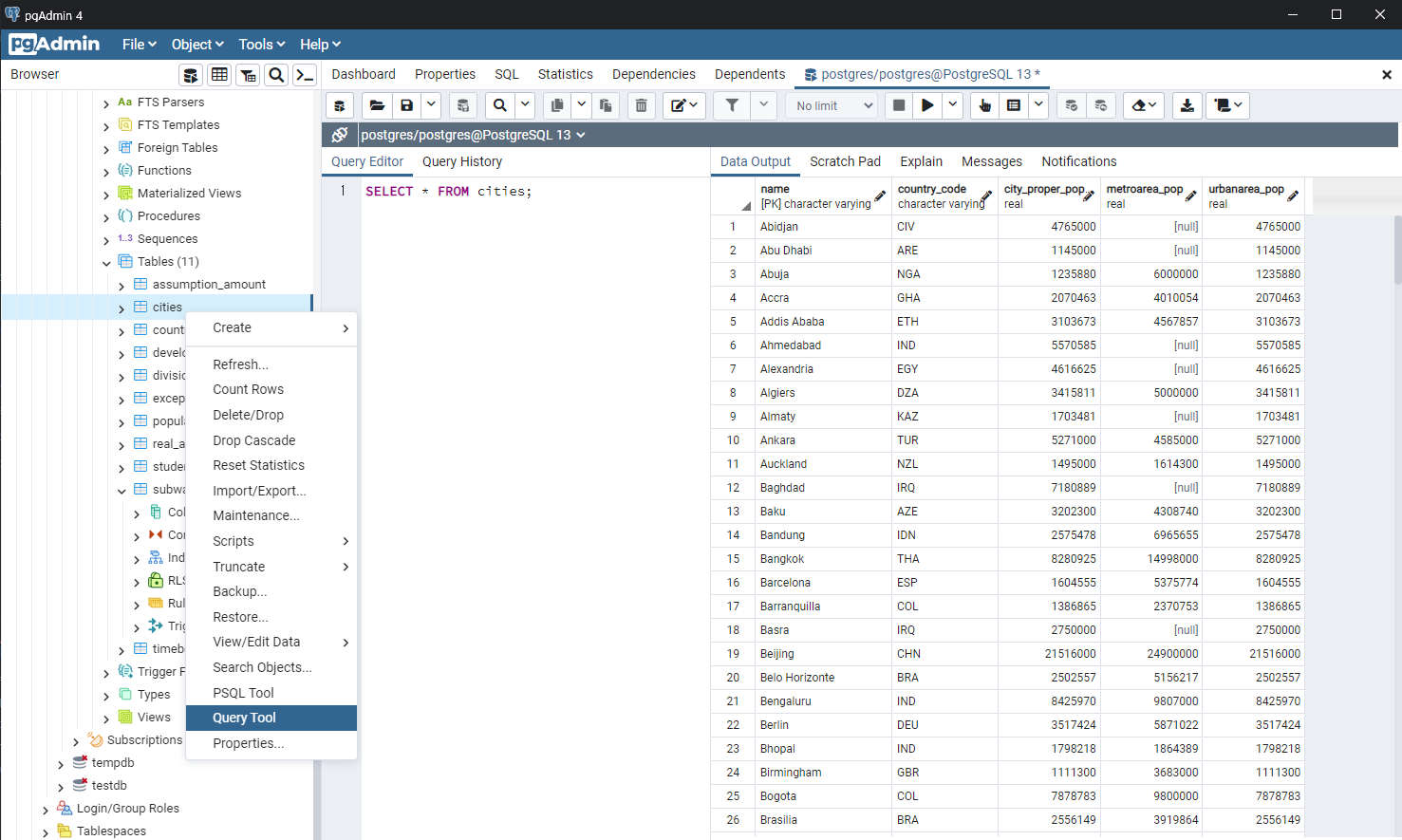
select*from cities; -- name
select*from countries; -- capital
-- 메인쿼리 -- citi 테이블에서, name, country_code, urban_pop -- urban_pop 내림차순 정렬 -- 상위 5개만 출력 -- 서브쿼리 -- city 테이블에 name과 countries capital 매칭이 되는 애들만 조회 select name, country_code, urbanarea_pop -- 각 컬럼 출력 from cities -- cities 테이블에서 조회 where name in (select capital from countries) -- name컬럼 내부에 서브쿼리의 값과 같은값이 있는 경우만 orderby urbanarea_pop desc-- urbanarea_pop 컬럼 내림차순으로 정렬 limit 5; -- 상위 5개만
-- 결과물을 동일하게 -- 두개의 테이블을 JOIN SELECT countries.name AS country, COUNT(*) AS cities_num FROM cities INNERJOIN countries ON countries.code = cities.country_code -- 테이블 교집합 GROUPBY country -- country의 항목으로 묶어줌 ORDERBY cities_num DESC, country -- cities_num 컬럼을 내림차순으로 정렬, country 컬럼 출력 LIMIT 9; -- 상위 9개만
-- 서브쿼리를 where --> select 절로 옮긴 결과 select countries.name as country , (select count(*) from cities where countries.code = cities.country_code) as cities_num from countries orderby cities_num desc, country limit 9; -- 안보던 형식이라 그런지 더 복잡해 보인다.
자바스크립트는 브라우저를 통해 사용자와 상호작용한다. 마우스의 위치가 어디인지, 어떤값을 받아오는지, 스크롤이 어디쯤인지에 따라 각각의 이벤트를 지정할 수 있다. 그런데 당연하게도 그런 값을 받아오는건 브라우저나 자바스크립트가 별도의 코딩없이 척척해주지는 않는다. (적어도 내가 아는선에서는) 그런 자바스크립트에는 값을 받아오는 명령어가 있는데 그것이 바로 prompt()이다.
1
ex) prompt("What your name?")
prompt()는 alert() 처럼 팝업창이 뜨는데 alert와 다르게 값을 입력받을수 있다. 일단 입력은 모두 String타입으로 받아진다. 하지만 커스텀이 자유롭지못해서 요즘엔 잘 쓰이지 않고 있다고 한다.
typeof
파이썬에서의 type() 과 같은 역할을 한다. typeof a또는 typeof(a)처럼 객체나 변수의 타입을 출력해준다.
parseInt()
변수 a 가 있고, a가 숫자로만 이루어진 문자열(string)일 경우 parseInt(a) 는 내용은 같으나 타입은 number인 a를 반환해준다. 그러나 a 가 만약 문자로 이루어져있다면 대신 NaN(Not a Number)이 반환 된다.
조건문 (if만)
1 2 3 4 5 6 7
if (a<0) { console.log("a는 음수입니다."); } else if (a=0) { console.log("a는 0입니다."); } else { console.log("a는 양수입니다.); }
기본적으로 자바와 크게 다르지 않아 패스….
비교연산자
다른부분만 빠르게 체크하겠다. 자바스크립트에는 같다 라는 뜻의 ==와 같지 않다 라는 뜻의 !=가 있다. 하지만 ===와 !== 도 존재하는데 이는 ‘엄격하게 같다’와 ‘엄격하게 같지 않다’이다. ‘엄격하게’가 뜻하는 바는 비교하는 변수의 타입까지 고려한다는 뜻이다.
-- 명령어의 뜻은 다음과 같다. -- -U = 데이터베이스 사용자 이름 -- -d = 연결할 데이터 베이스 이름 -- -f = 파일 내부의 지정한 명령을 실행후 끝냄 -- -o = 쿼리 결과를 파일(또는 |파이프)로 보냄 -- -F = unaligned 출력용 필드 구분자 설정(기본값: "|") -- -A = 정렬되지 않은 표 형태의 출력 모드 -- -t = 행만 인쇄
어후 복잡하다.
그래도 psql --help를 입력하면 모든 명령어가 출력되니 참고하며 쓰면 된다.
위의 명령어를 입력하면 DB의 암호 입력창이 나오는데 DB를 만들때 입력했던 암호를 입력하면 csv생성이 완료된다.
dump파일 업로드
dump파일이 있는 폴더로 이동하고 다음 명령 입력시 데이터 베이스에 테이블 각각 생성됨. psql -U postgres -d postgres -f function_example.dump 유저네임, DB이름, 파일이름에따라 명령어를 알맞게 바꿔주어야 함. 명령어에 대한 설명은 바로 위에 있고, psql --help를 해도 볼 수 있음.
-- 테이블 생성 create table develop_book( book_id integer , date date , name varchar(80) );
-- 등록된 테이블 리스트 조회 -- CMD 창에서 \dt 실행하면 동일한 리스트 확인 가능 SELECT * FROM pg_catalog.pg_tables WHERE schemaname != 'pg_catalog' AND schemaname != 'information_schema';
-- 테이블 삭제 drop table develop_book;
-- 테이블 생성 create table develop_book( book_id integer , date date , name varchar(80) );
-- 데이터 자료 추가하기 insert into develop_book values(1, '2021-12-22', 'SQL 레시피');
-- 큰 따옴표 입력 insert into develop_book values(2, '2021-12-23', '"자바의 정석"');
-- 작은 따옴표 입력 insert into develop_book values(3, '2021-12-24', '''자바의 정석''');
-- Let's go 입력 insert into develop_book values(4, '2021-12-25', 'I''am book');
-- 조회 하기 select * from develop_book;
-- 테이블에 자료 여러 개 추가하기 insert into develop_book values (5, '2021-12-30', '책1'), (6, '2021-12-30', '책2'), (7, '2021-12-30', '책3'), (8, '2021-12-30', '책4');
-- 조회 하기 select * from develop_book;
-- 컬럼 선택 조회 select book_id, name from develop_book;
-- Limit 명령어 select * from develop_book limit 3;
-- OFFSET 명령어 추가 -- ~번째 인덱스부터 시작 select * from develop_book limit 5 offset 2;
-- ORDER BY -- 오름차순 select * from develop_book order by name asc;
select * from develop_book order by name desc;
-- WHERE 조건문 select * from develop_book where book_id = 5;
select * from develop_book where book_id <> 5; -- 5 제외
-- AS 명령어 select name as 책제목 from develop_book;
-- Coalesc 함수 -- 데이터 조회 시, NULL 값을 다른 기본 값으로 치환 -- ex) NULL --> "데이터 없음"
insert into student_score(name, score) values ('Hello', NULL), ('Hi', NULL);
-- 조회 select id , name , score , case when score <= 100 and score >= 90 then 'A' when score <= 89 and score >= 80 then 'B' when score <= 79 and score >= 70 then 'C' when coalesce (score,0) <= 69 then 'F' end from student_score;
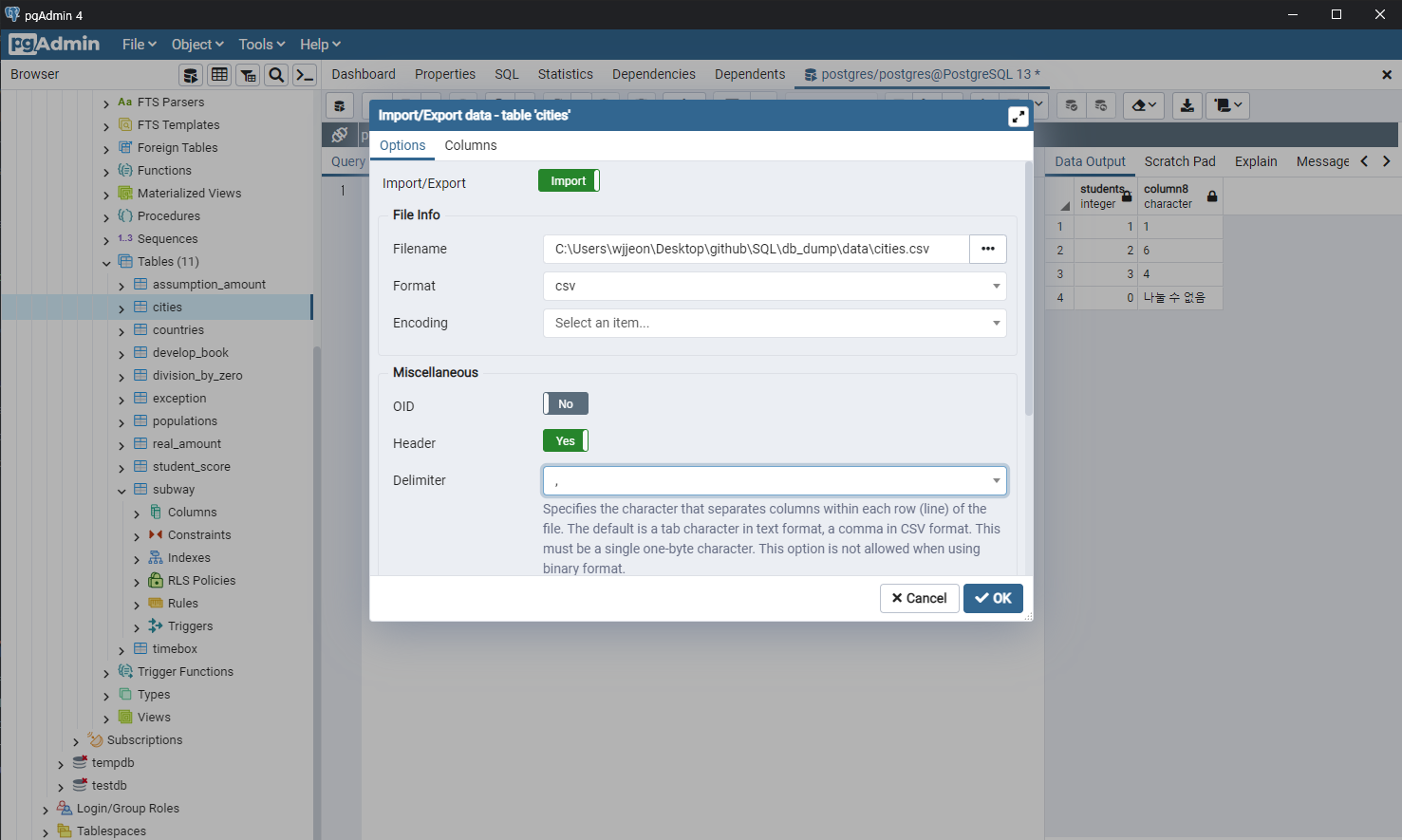
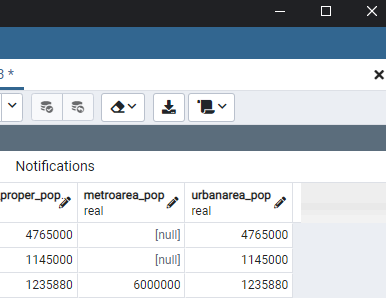
-- 결측치 처리 select students , coalesce((12/nullif(students, 0))::char, '나눌 수 없음') as column8 from division_by_zero;