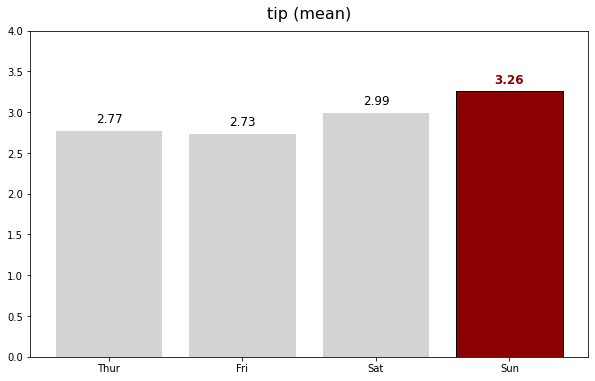
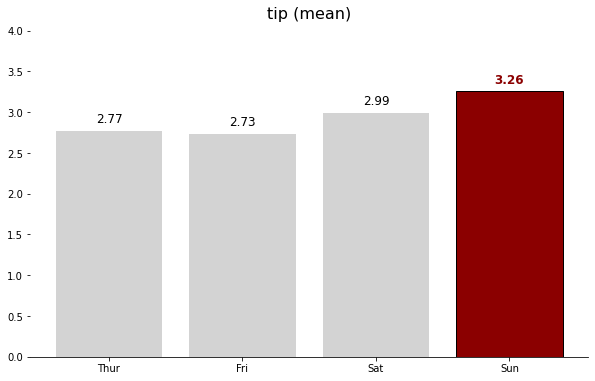
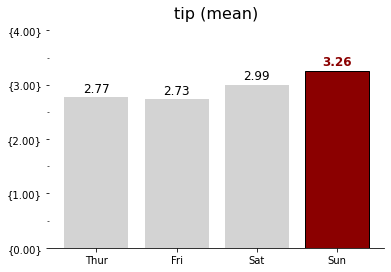
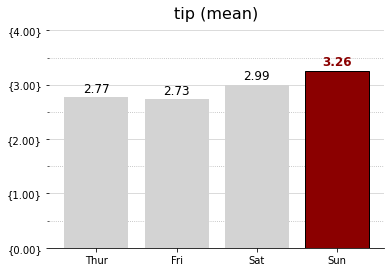
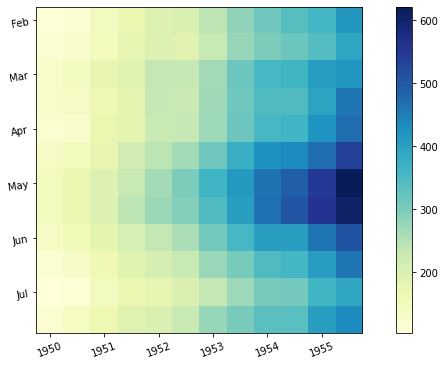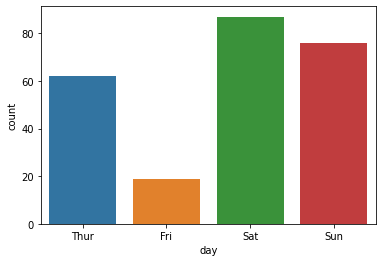파이썬을 배운지 며칠 되지 않아 kaggle이라는 예측모델 및 분석대회 플랫폼의 데이터 분석 대회에 참가하게 되었다. 주제는 2021년 캐글러kaggler들에게 설문조사이며, 그 설문조사 데이터셋을 바탕으로 참가자가 분석을 하여 참가자만의 주제에 그래프와 수치로 답을 찾아내는 대회이다.
데이터셋에 있는 캐글러의 수는 19년 19717명, 21년 25974명, 직업은 데이터사이언스, 데이터 엔지니어부터 학생까지 다양하며, 나이, 학력, 국적, 라이브러리, 언어 등 매우 다양한 항목들이 있다.
우리 조에서 처음으로 선정하려 했던 주제는 한국, 일본, 중국의 캐글러의 트렌드변화로 하려 했으나, 중국, 일본에 비해 데이터가 턱없이 부족해 비교가 무의미한 수준이었기에 캐글러의 수가 비슷한 두 나라인 중국과 일본로 선정했다.(의외로 중국의 캐글러 절대적인 수가 인구에 비해 상당히 적어 일본보다 조금 적은편이였다.)
import(Kaggle notebook)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import numpy as np import pandas as pd import matplotlib.pyplot as plt import plotly.express as px import plotly.graph_objects as go from warnings import filterwarnings from plotly.subplots import make_subplots filterwarnings('ignore')
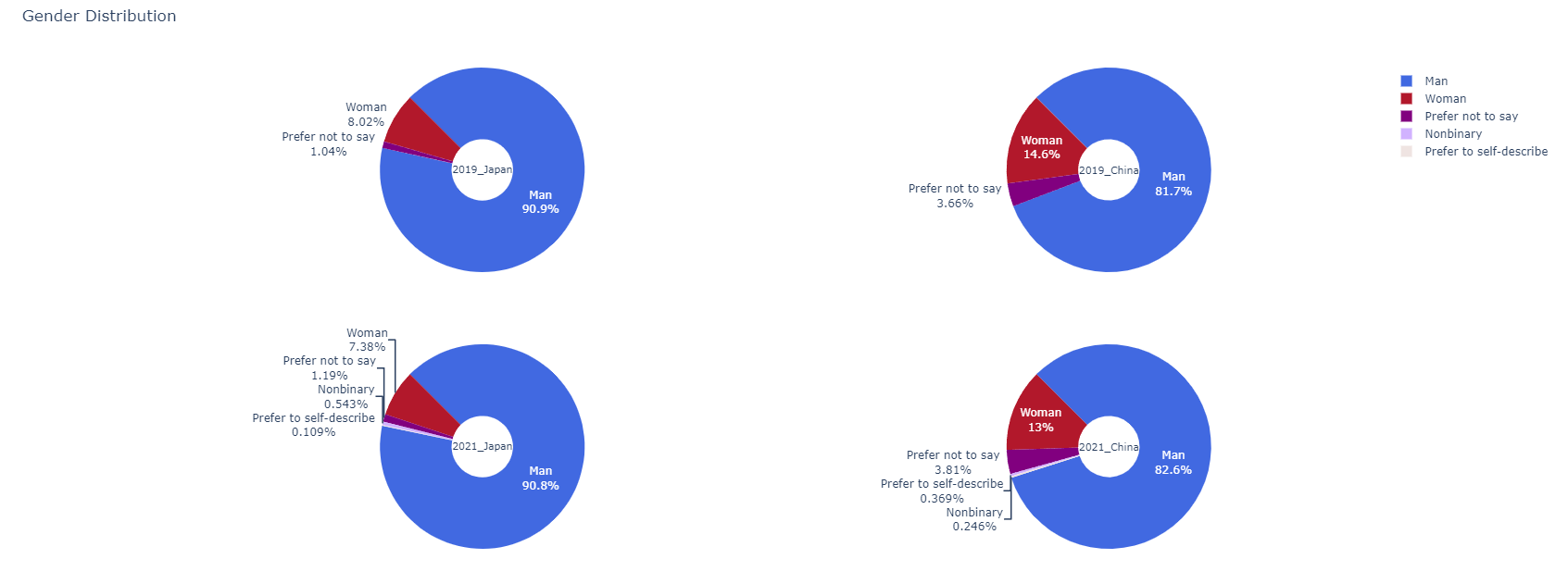
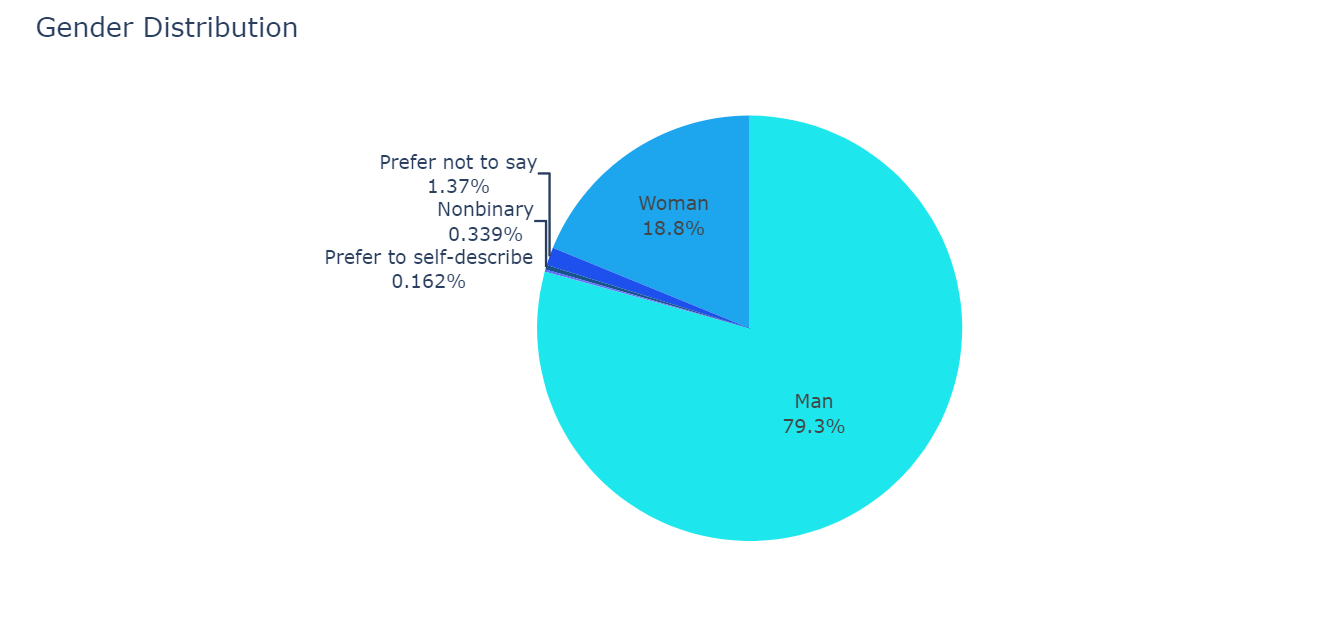
두번쨰 질문에 답하기 위해 일본과 중국의 캐글러 성별분포를 도넛모양으로 나타낸 그래프이다. 각각의 그래프는 국가,년도(2019, 2021)별로 각각 나누었고 그래프의 항목은 Man Woman Prefer not to say Nonbinary Prefer to self-describe 이렇게 다섯가지로 나누었다.
그림처럼 마커의 모양을 변경 할 수 있다. color옵션은 헥스코드와 rgb값 모두 가능하며, 모양의 경우 매우 다양하므로 포스팅 최하단에 링크를 첨부한다.
박스플롯 (box plot)
박스플롯이란??
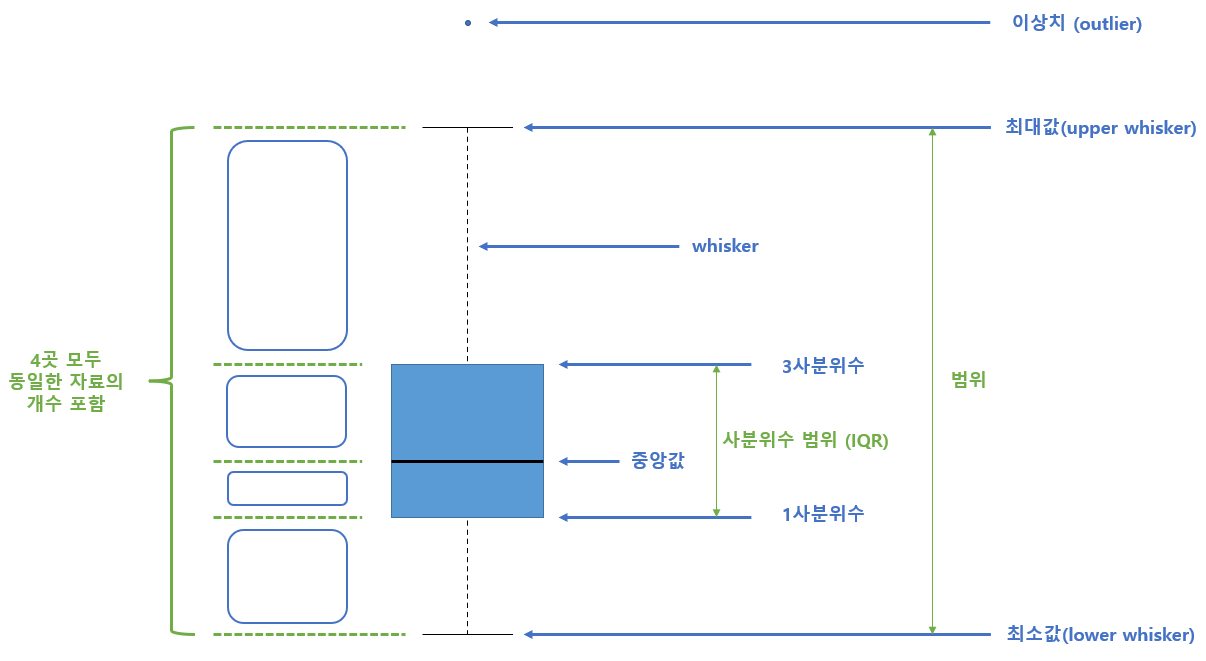
‘박스플롯’box plot,또는 ‘상자 수염 그림’은 수치적 자료를 나타내는 그래프이다. 이 그래프는 가공하지 않은 자료 그대로를 이용하여 그린 것이 아니라, 자료로부터 얻어낸 통계량인 ‘5가지 요약 수치’five-number summary 를 가지고 그린다. 이 때 5갸지 요약 수치란 최솟값, 제 1사분위(Q1),제 2사분위(Q2), 제 3사분위(Q3), 최댓값을 일컫는 말이다. 히스토그램과는 다르게 집단이 여러개인 경우에도 한 공간에 수월하게 나타낼수 있다.
언제 사용되는가??
박스 플롯을 사용하는 이유는 데이터가 매우 많을때 모든 데이터를 한눈에 확인하기 어려우니 그림을 이용해 데이터 집합의 범위와 중앙값을 빠르게 확인 할 수 있는 목적으로 사용한다. 또한, 통계적으로 이상치outlier가 있는지도 확인이 가능하다.
박스플롯의 구성
박스플롯을 처음 접한다면 박스플롯을 어떻게 해석해야 하는지 난해할수 있다. 다음 그림에서 박스플롯의 각 구성이 무엇을 의미하는지 간단하게 알아보자. 각 요소들을 설명하면 다음과 같다.
요소
설명
이상치(outlier)
최소값보다 작은데이터 또는 최대값보다 큰 데이터가 이상치에 해당한다
최대값(upper whisker)
‘중앙값 + 1.5 × IQR’보다 작은 데이터 중 가장 큰 값
최소값(lower whisker)
‘중앙값 - 1.5 × IQR’보다 큰 데이터 중 가장 작은 값
IQR(Inter Quartile Range)
제3사분위수 - 제1사분위수 실수 값 분포에서 1사분위수(Q1)와 3사분위수(Q3)를 뜻하고 이 3사분위수와 1사분위수의 차이(Q3 - Q1)를 IQR라고 한다.
중앙값
박스내부의 가로선, 용어 그대로 중앙값이다
whisker
상자의 상하로 뻗어있는 선
Plotly로 박스플롯 작성하기
1 2 3 4 5 6 7 8 9 10 11
import numpy as np import pandas as pd import matplotlib.pyplot as plt
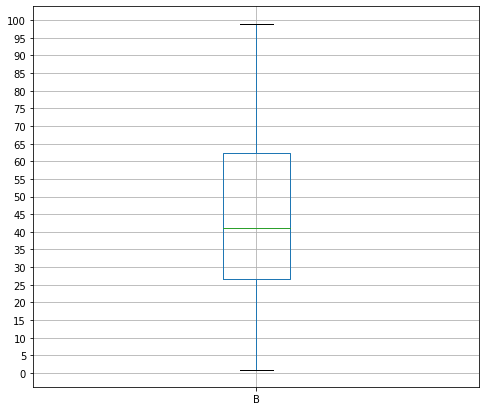
df3 = pd.DataFrame(np.random.randint(0, 100, (100, 2)), columns=['A', 'B']) #임의로 수 생성
plt.figure(figsize=(8,7)) # 크기 지정 boxplot = df3.boxplot(column=['B']) # df3의 'B'컬럼을 박스플롯으로 생성 plt.yticks(np.arange(0,101,step=5)) # 박스플롯이 그려질 범위 지정 plt.show()
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python # For example, here's several helpful packages to load
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory # For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All" # You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
1 2
from plotly.offline import plot, iplot, init_notebook_mode init_notebook_mode(connected=True)
1 2 3 4 5 6 7 8 9 10 11 12
import numpy as np import pandas as pd import matplotlib.pyplot as plt import plotly.express as px import plotly.graph_objects as go from warnings import filterwarnings filterwarnings('ignore')
fig = go.Figure(data=[ -> 그래프의 기본적인 틀을 설정하는 함수이고, fig에 데이터를 부여해준다.
go.Pie( -> 그래프의 형태가 파이모양(원그래프)임을 의미한다.
labels = df['Q2'][1:].value_counts().index -> 그래프로 표현될 값에 붙일 이름이다. 이 코드에서는 ‘df’의 ‘Q2’열에 있는 데이터의 ‘1번인덱스(질문열을 제외하기 위함) 행부터 마지막까지’ 카운트하고 값에따라 분류했을 때의 인덱스열 인 것이다.
values = df['Q2'][1:].value_counts().values -> 그래프로 표현될 값이다. 이 코드에서는 ‘df’의 ‘Q2’열에 있는 데이터의 ‘1번인덱스 행부터 마지막까지’ 카운트하고 값에따라 분류했을 때의 값(각 값을 카운트한 값) 이다.
textinfo = 'label+percent' -> 그래프에 표시된 항목에 나타낼 텍스트를 설정한다. 이 코드에서는 항목명(label)과 비율(percent)을 나타낸다.
1 2 3 4 5 6
fig.update_traces( marker=dict(colors=colors[2:])) # 그래프를 어떤 색으로 표현할 것인가를 설정 fig.update_layout( # 그래프의 부가정보 설정 title_text='Gender Distribution', # 그래프 제목 showlegend=False) # 범례표시여부 fig.show()
fig.update_traces( -> 추가바람
marker=dict(colors=colors[2:])) -> 그래프의 색상을 설정한다. 이 코드에서는 위에서 설정된 colors 리스트에서 2번 인덱스부터 순서대로 사용한다.
fig.update_layout( -> 그래프의 부가정보를 설정한다.
title_text='Gender Distribution' -> 그래프의 제목을 설정한다.
showlegend=False) -> 범례의 표기여부를 결정한다. 이 코드에서는 False이므로 범례가 표기되지 않는다.
fig.show() -> 화면에 그래프를 표시하는 기능을한다. 몇몇에디터에서는 자동으로 표시되기때문에 호출할 필요가 없는 경우가 있다.
man = df[df['Q2'] == 'Man']['Q1'].value_counts() # 성별이 남성[df['Q2'] == 'Man']인 행에서 나이['Q1']의 값을 카운트하여 시리즈로 만듦. woman = df[df['Q2'] == 'Woman']['Q1'].value_counts() # 성별이 여성[df['Q2'] == 'Woman']인 행에서 나이['Q1']의 값을 카운트하여 시리즈로 만듦. textonbar_man = [ # list comprehension = [(변수를 활용한 값) for (사용할 변수 이름) in (순회 할 수 있는 값)] round((m/(m+w))*100, 1) for m, w inzip(man.values, woman.values)] # for문을 사용하여 round함수의 계산을 하고 textonbar_man에 저장 textonbar_woman = [ # list comprehension round((w/(m+w))*100, 1) for m, w inzip(man.values, woman.values)]
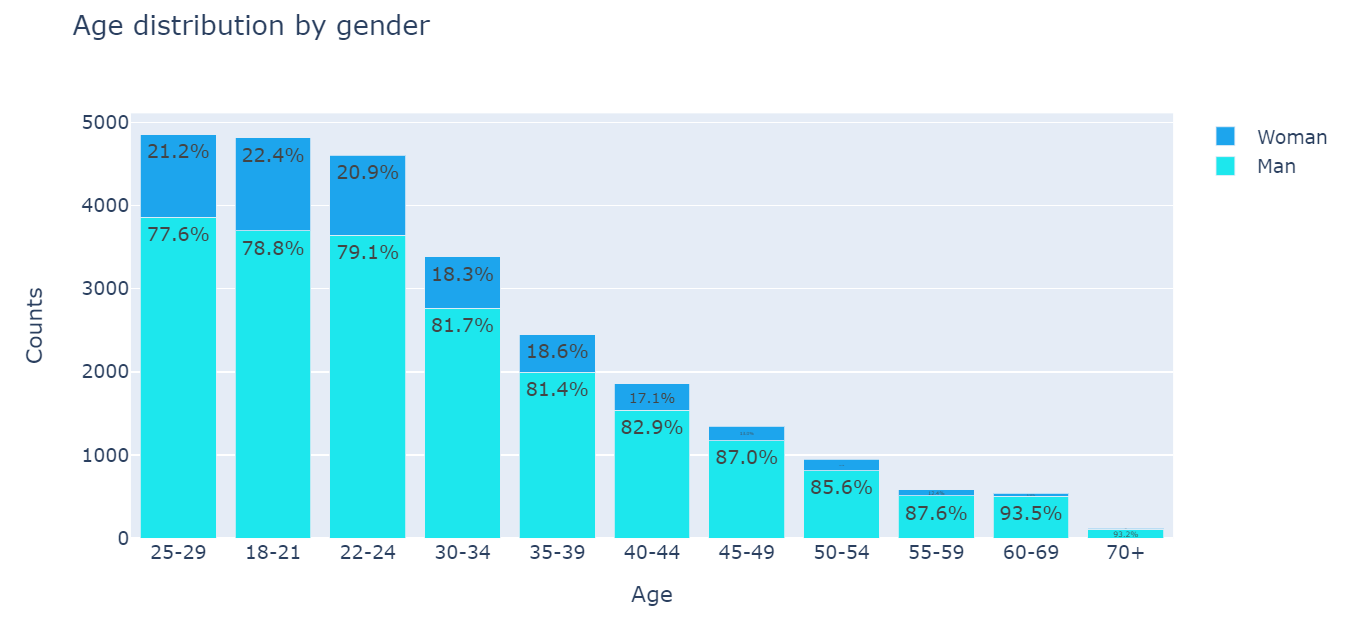
# go = graph_objects fig = go.Figure(data=[ go.Bar( # 막대그래프 name='Man', # 그래프로 나타낼 항목 x=man.index, # x축에 man의 인덱스 y=man.values, # y축에 man의 값 text=textonbar_man, # 막대의 값을 작성해줄 텍스트 marker_color=colors[2]), #막대 색 go.Bar( name='Woman', x=woman.index, y=woman.values, text=textonbar_woman, marker_color=colors[3]) ]) fig.update_traces( texttemplate='%{text:.3s}%', # fig(print(fig)로 출력가능)내부의 text 인자를 차례대로 출력 (그래프의 위의 텍스트를 표현) textposition='inside') # 그래프상에서 값의 위치 fig.update_layout( barmode='stack', # 막대의 형태 title_text='Age distribution by gender', # 그래프 제목 xaxis_title='Age', # x축 제목 yaxis_title='Counts') # y축 제목 fig.show()
그래프
코드 해석
1 2 3 4
man = df[df['Q2'] == 'Man']['Q1'].value_counts() woman = df[df['Q2'] == 'Woman']['Q1'].value_counts() textonbar_man = [ round((m/(m+w))*100, 1) for m, w inzip(man.values, woman.values)] textonbar_woman = [ round((w/(m+w))*100, 1) for m, w inzip(man.values, woman.values)]
man = df[df['Q2'] == 'Man']['Q1'].value_counts() -> 성별이 남성[df['Q2'] == 'Man]인 행에서 나이['Q1']의 값을 카운트하여 시리즈를 생성한다.
woman = df[df['Q2'] == 'Woman']['Q1'].value_counts() -> 성별이 여성[df['Q2'] == 'Woman']인 행에서 나이['Q1']의 값을 카운트하여 시리즈를 생성한다.
textonbar_man = [round((m/(m+w))*100, 1) for m, w in zip(man.values, woman.values)] -> for문을 사용하여 round함수를 계산 하고 textonbar_man에 저장한다.
textonbar_woman = [round((uw/(m+w))*100, 1) for m, w in zip(man.values, woman.values)] -> for문을 사용하여 round함수를 계산 하고 textonbar_woman에 저장한다.
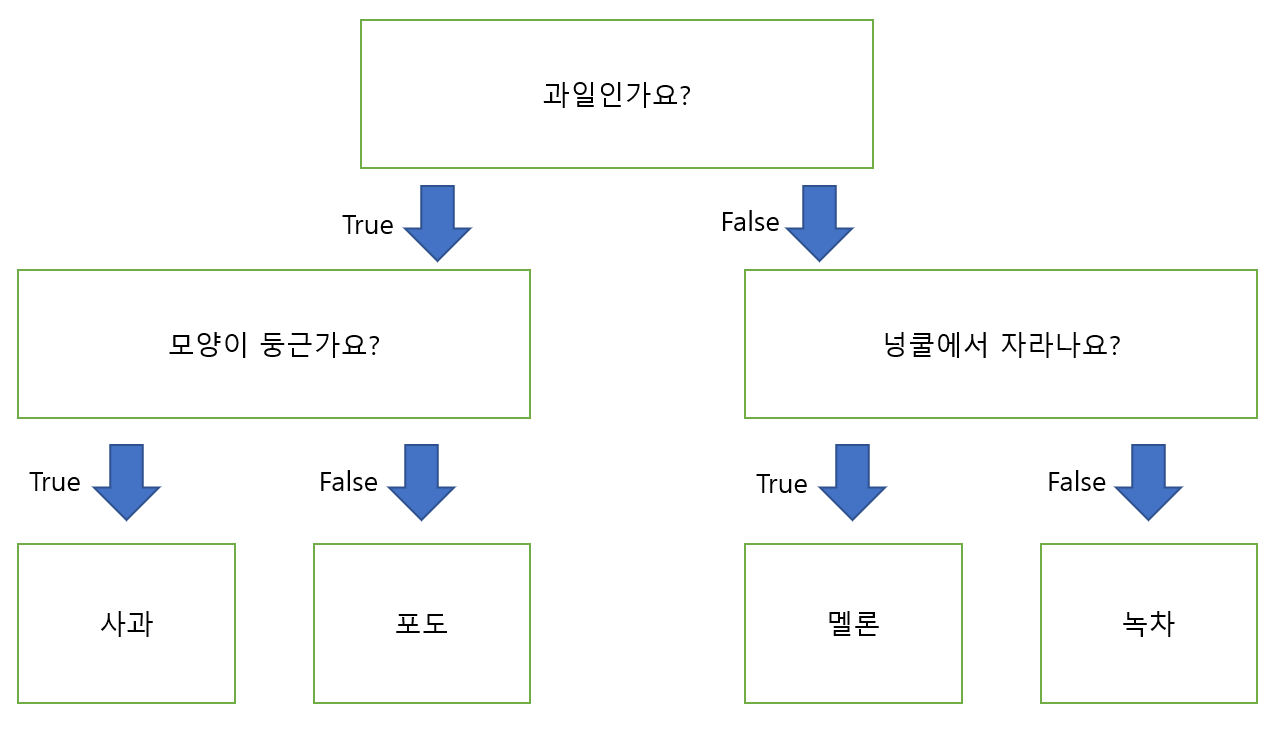
결정 나무가 행하는 이 과정은 ‘스무고개’를 할때의 그것과 비슷하다. 사과, 포도, 멜론, 녹차를 구분한다고 생각해보자. 사과와 포도는 과일이고 멜론과 녹차는 과일이 아니다. ‘과일인가요?’라는 질문을 통해 사과, 포도 / 멜론, 녹차를 나눌 수 있고, 사과와 포도는 ‘(과실 전체의)모양이 둥근가요?’, 멜론과 녹차는 ‘넝쿨에서 자라나요?’ 라는 질문을 통해 분류해 낼 수 있다. 위의 결정나무를 도식화하면 아래와 같다.
이렇게 질문에 따라 데이터를 구분짓는 모델을 결정나무모델이라고 한다. 한번의 질문에 True 혹은 False를 통해 변수영역을 두 개로 분기한다.
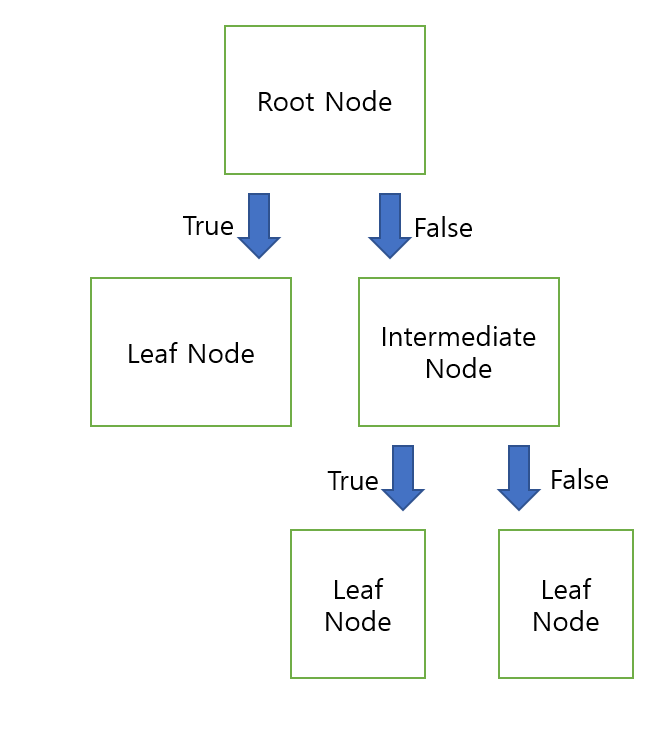
위의 그림에서 각각의 네모상자를 노드Node라고 하며, 가장 처음의 분기점을 Root Node라고 하고, 가장 마지막 노드를 Leaf Node또는 Terminal Node라고 한다.
결정나무분류기 = DecisionTreeClassifier
DecisionTreeClassifier()는 결정나무의 기능을 바꿀수 있는 파라미터인데 파라미터 내부의 특성 하나하나를 하이퍼파라미터라고 한다.
DecisionTreeClassifier()파라미터의 괄호 안에 각각의 값을 입력할 수 있는데 다음과 같은 항목들이 있다.
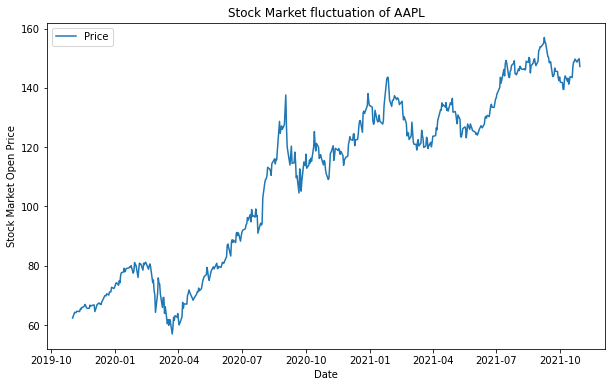
data에 담겨있는 애플의 주가정보 중 ‘Open’에 해당하는 전일 종가를 가장 앞쪽(.head())부터 출력한 것이다. 애플주식이 이렇게 쌌었나 검색해보니 이게 맞다….
방법 1. Pyplot API
1 2 3 4 5 6 7 8 9 10 11 12 13
# import fix_yahoo_finance as yf import yfinance as yf import matplotlib.pyplot as plt
data = yf.download('AAPL', '2019-11-01', '2021-11-01') ts = data['Open'] plt.figure(figsize=(10,6)) plt.plot(ts) plt.legend(labels=['Price'], loc='best') plt.title('Stock Market fluctuation of AAPL') plt.xlabel('Date') plt.ylabel('Stock Market Open Price') plt.show()
Output
[*********************100%***********************] 1 of 1 completed
이처럼 결과가 출력되지만 이 문법은 시각화를 처음배우는 초심자에게는 적합하지 않다고 한다. 후술할 문법과 위 문법 모두 출력은 되나 이 문법은 객체지향이 아니기도 하고 상대적으로 복잡하기때문에 초심자의 경우에 헷갈릴수 있어 사용하지 않는다. 구글링 했을때 객체.이 아닌 plt.으로 시작하는 애들이 있다면 그 코드는 스킵하는게 좋다.
방법 2. 객체지향 API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas from matplotlib.figure import Figure import matplotlib.pyplot as plt
fig = Figure()
import numpy as np np.random.seed(6) x = np.random.randn(20000)
.xticks()는 x축의 눈금을 나타내는 메소드인데 기본적으로는 list자료형 한개을 사용한다. 하지만 메소드에 인자가 ‘list’ 두 개로 받아졌을 경우, 첫번째 list는 x축 눈금의 갯수가 된다. 두번째 list는 x축 눈금의 이름이 된다. 이 코드에서는 rotation 옵션도 들어가 있는데 이것은 그냥 이름을 몇도정도 기울일지 나타낸다.
plot = ax.bar()는 그래프를 막대로 만든다. 첫번째 리스트 인자의 수 만큼 막대가 생성되고, 두번째 리스트 인자의 값 만큼 막대가 길어진다. 이렇다보니 첫번째 리스트와 두번째 리스트의 인자의 수가 일치해야 에러가 나지 않는다.
for문 내부의 ax.text()는 Seaborn-막대그래프-표현할 값이 한 개인 막대 그래프 챕터에 서술했으니 참고하길 바란다.
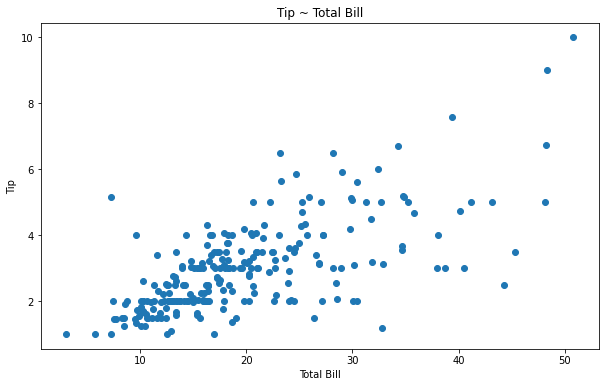
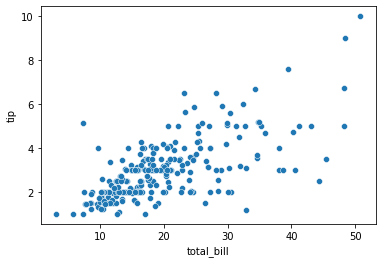
산점도 그래프
두개의 연속형 변수 (키, 몸무게 등)
상관관계 != 인과관계
나타내는 값이 한가지인 산점도 그래프
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import matplotlib.pyplot as plt import seaborn as sns
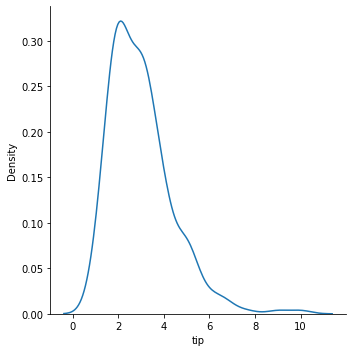
# 내장 데이터 tips = sns.load_dataset("tips") x = tips['total_bill'] y = tips['tip']
fig, ax = plt.subplots(figsize=(10, 6)) ax.scatter(x, y) # 각각의 값을 선으로 표현해주는 scatter() ax.set_xlabel('Total Bill') ax.set_ylabel('Tip') ax.set_title('Tip ~ Total Bill')
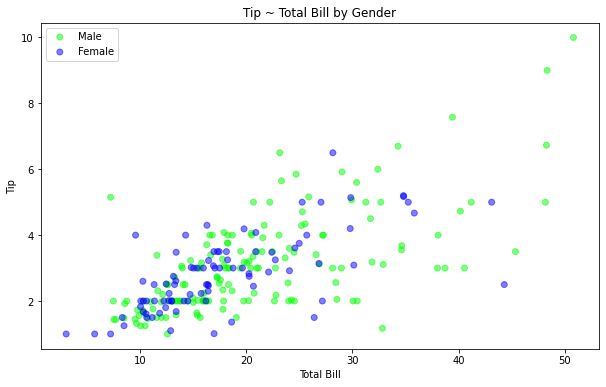
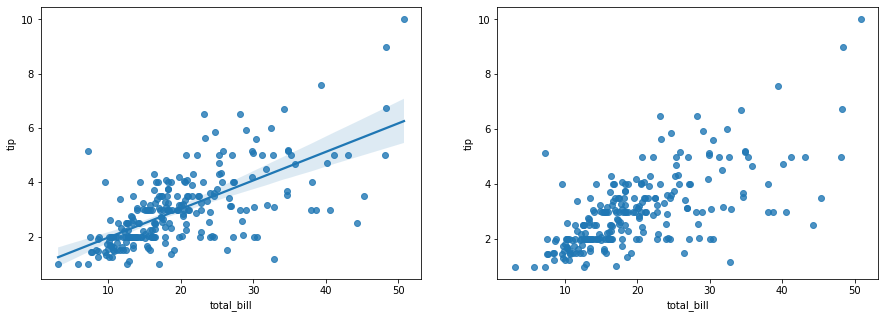
fig, ax = plt.subplots(figsize=(10, 6)) for label, data in tips.groupby('sex'): ax.scatter(data['total_bill'], data['tip'], label=label, color=data['sex_color'], alpha=0.5) ax.set_xlabel('Total Bill') ax.set_ylabel('Tip') ax.set_title('Tip ~ Total Bill by Gender')
ax.legend() fig.show()
Output
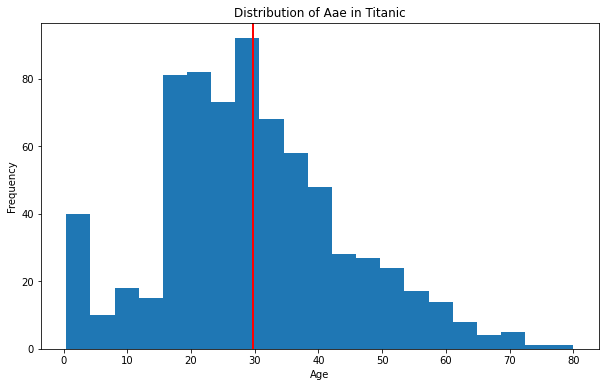
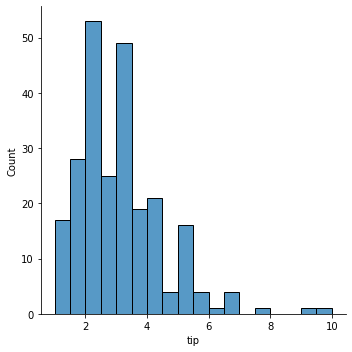
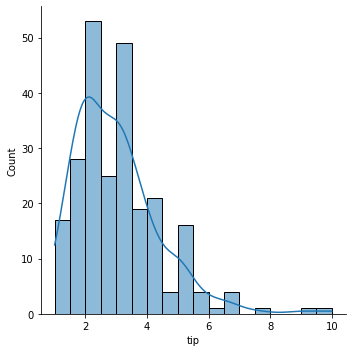
히스토그램
수치형 변수 1개
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import matplotlib.pyplot as plt import numpy as np import seaborn as sns
# 내장 데이터 titanic = sns.load_dataset('titanic') age = titanic['age']
nbins = 21 fig, ax = plt.subplots(figsize=(10, 6)) ax.hist(age, bins = nbins) # 여기서 bins = nbins는 히스토그램을 더 세밀하게 나누어 준다. ax.set_xlabel("Age") ax.set_ylabel("Frequency") ax.set_title("Distribution of Aae in Titanic") ax.axvline(x = age.mean(), linewidth = 2, color = 'r') fig.show()
Output
코드
설명
.hist()
데이터를 히스토그램으로 표현해주는 메소드
.axvline()
데이터의 평균을 선으로 나타내주는 메소드
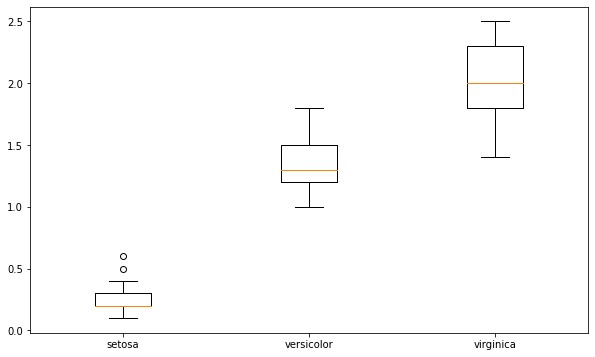
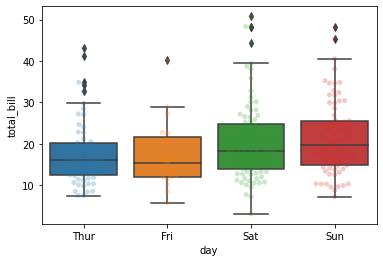
박스플롯
x축 변수: 범주형 변수, 그룹과 관련있는 변수, 문자열
y축 변수: 수치형 변수
1 2 3 4 5 6 7 8 9 10 11 12 13
import matplotlib.pyplot as plt import seaborn as sns
iris = sns.load_dataset('iris')
data = [iris[iris['species']=="setosa"]['petal_width'], iris[iris['species']=="versicolor"]['petal_width'], iris[iris['species']=="virginica"]['petal_width']]
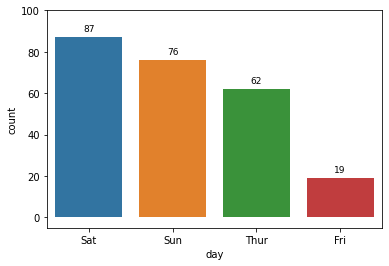
Fri 19
Thur 62
Sun 76
Sat 87
Name: day, dtype: int64
표현할 값이 한 개인 막대 그래프
1 2 3 4 5 6 7
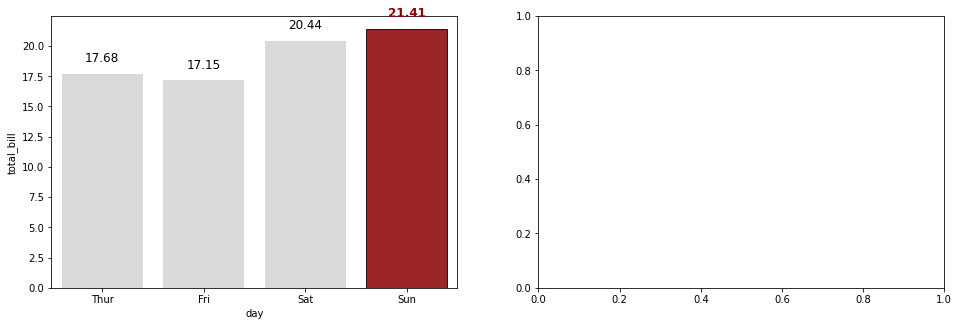
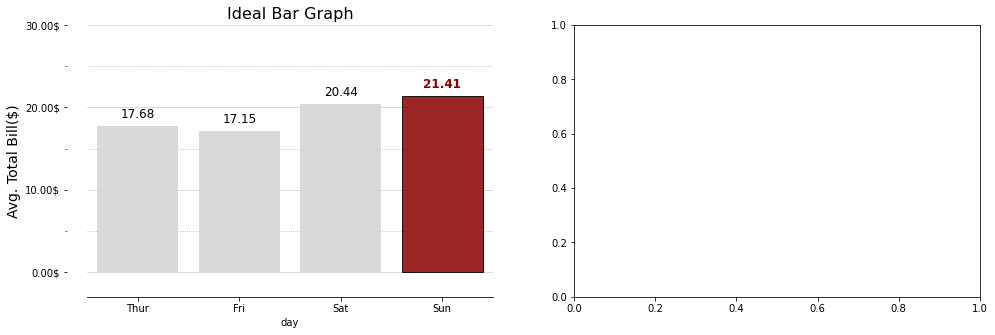
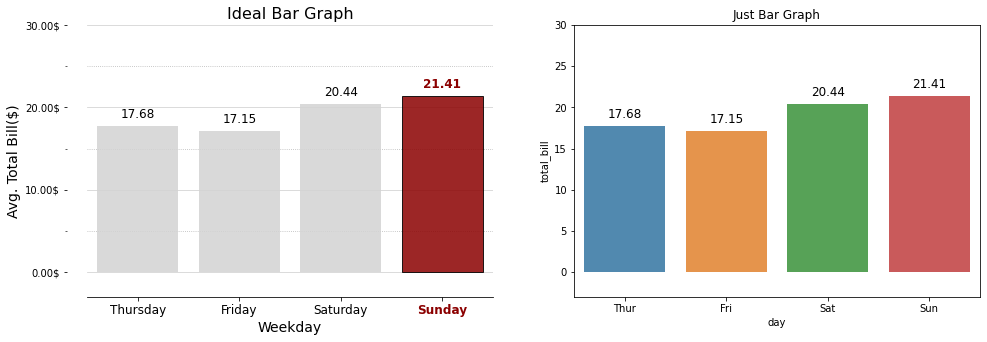
# 기본주석 생략 ax = sns.countplot(x = "day", data = tips, order = tips['day'].value_counts().index) # x축을 'day'로 지정, data는 'tips'로 채워넣음, 'day'의 값이 높은 순서대로 막대그래프 정렬 for p in ax.patches: # ax.patches = p height = p.get_height() # 아래행을 실행하기위해 막대그래프의 높이 가져옴 ax.text(p.get_x() + p.get_width()/2., height+3, height, ha = 'center', size=9) # 막대그래프 위 수치 작성 ax.set_ylim(-5, 100) # y축 최소, 최대범위 plt.show()
Output
나중에 다시 본다면 조금 설명이 필요할 것 같다. 특히 ax.text행의 인자가 조금 많은데 설명이 필요한 듯하다. 직접 colab에서 이것저것 만져본 결과 추측하기로는 다음 표과 같은듯 하다.
코드
설명
p.get_x() + p.get_width()/2.
수치가 들어갈 x축 위지
height+3
y축 위치(현재 +3)
height
수치의 값을 조절할 것인지(현재 +0)
ha = ‘center’
수치를 (x,y)축의 가운데로 정렬
size=9
폰트의 크기이다
여기서 혹시나 ha = 'center'부분이 잘 이해가 안될수 있다.내가그랬다 ha =는 (x,y)축의 기준이 될 곳을 정하는 인자인듯 하다. center말고도 left,right등을 사용할수 있는데 막대의 기준에서 왼쪽,오른쪽이 아닌 텍스트의 기준에서 왼쪽,오른쪽이라 방향을 선택하면 오히려 반대로 배치되는것을 알 수 있다.
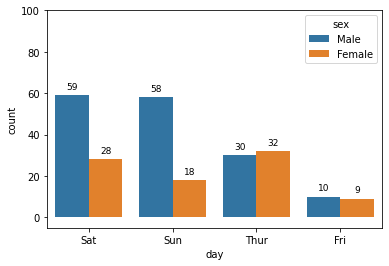
표현할 값이 두 개인 막대 그래프
1 2 3 4 5 6 7 8 9
# 기본주석 생략 ax = sns.countplot(x = "day", data = tips, hue = "sex", dodge = True, order = tips['day'].value_counts().index) for p in ax.patches: height = p.get_height() ax.text(p.get_x() + p.get_width()/2., height+3, height, ha = 'center', size=9) ax.set_ylim(-5, 100)
plt.show()
Output
이 코드에서 첫째줄의 인자를 표로 나타내면
코드
설명
x = “day”
x축이 나타낼 자료
data = tips
표현할 데이터셋
hue = “sex”
그래프로 표현할 항목
dodge = True
항목끼리 나눠서 표현할 것인지
order = tips[‘day’].value_counts().index
‘day’의 값이 높은 순서대로 그래프 정렬
sns.countplot() x축이 나타낼 자료, 나타낼 데이터셋, 그래프로 나타낼 항목, 항목끼리 나눠서 표현할것인지, ‘day’의 값이 높은 순서대로 막대그래프 정렬
상관관계 그래프
데이터 불러오기 및 행, 열 갯수 표시하기
1 2 3 4 5 6 7 8 9 10
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
mpg = sns.load_dataset("mpg") print(mpg.shape) # 398 행, 9개 열
num_mpg = mpg.select_dtypes(include = np.number) # num_mpg에 'mpg' 데이터셋의 데이터타입 총갯수를 입력한다(숫자형 데이터타입만 포함) print(num_mpg.shape) # 398 행, 7개 열 (두개가 사라진 이유는 number타입이 아닌 Object타입이기 때문)
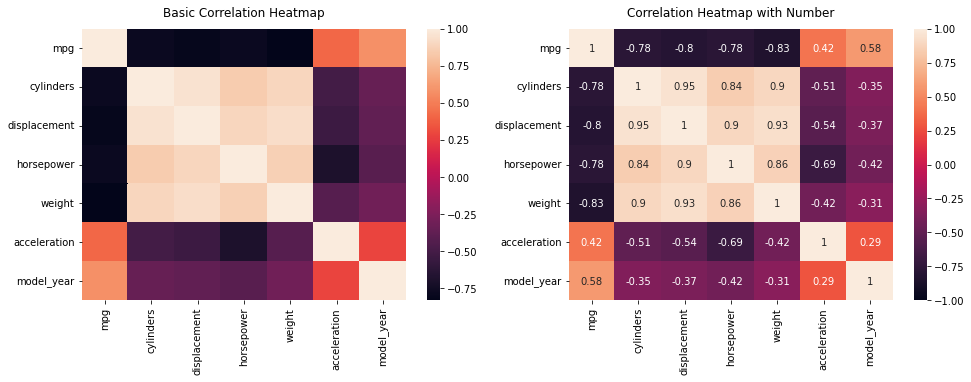
# 기본 그래프 [Basic Correlation Heatmap] sns.heatmap(num_mpg.corr(), ax=ax[0]) ax[0].set_title('Basic Correlation Heatmap', pad = 12)
# 상관관계 수치 그래프 [Correlation Heatmap with Number] sns.heatmap(num_mpg.corr(), vmin=-1, vmax=1, annot=True, ax=ax[1]) ax[1].set_title('Correlation Heatmap with Number', pad = 12)
plt.show()
Output
위의 코드에서 pad는 히트맵과 타이틀의 간격설정이며, set_title의 인자를 설명하면 (히트맵을 만들 ‘데이터셋.corr()’, 히트맵의 최소값, 최대값, 수치표현(bool값), 마지막인자는 확실하지는 않지만 앞의 히트맵 설정을 어떤 히트맵에 적용시킬지 묻는것 같다.)
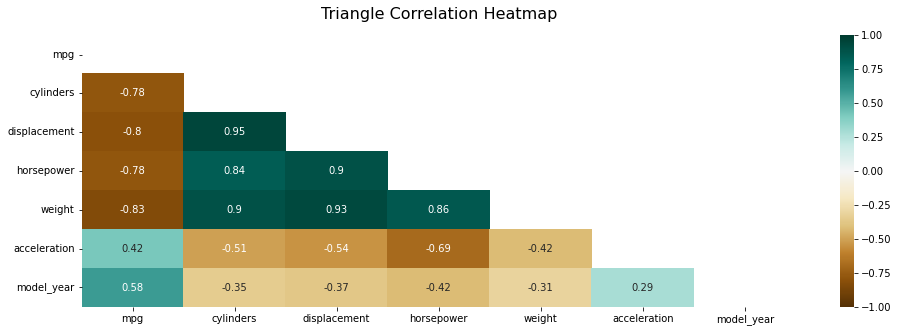
상관관계 배열 만들기
1 2 3 4
# import numpy as np # 윗단 코드에서 만들어진 num_mpg 사용 print(int(True)) np.triu(np.ones_like(num_mpg.corr()))
np.triu(배열, k=0)는 위 결과처럼 우하향 대각선이 있고 위 아래로 삼각형이 있다 생각했을때 아래쪽의 삼각형이 모두 0이 되는 함수이다. k의 숫자가 낮아질수록 삼각형은 한칸씩 작아진다. 위 결과에서 행과 열이 7칸이 된 이유는 np.ones_like(num_mpg.corr())의 행이 7개 이기때문인듯 하다. 확실히 모르겠음 질문 필수
이 챕터의 내용은 코드가 너무 긺으로 시각화 결과물을 접지않고 코드를 접는형식으로 서술하겠음.
필수 코드이므로 생략을 생략
1 2 3 4
import matplotlib.pyplot as plt from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter) import seaborn as sns import numpy as np
import matplotlib.pyplot as plt from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter) import seaborn as sns import numpy as np
import matplotlib.pyplot as plt from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter) import seaborn as sns import numpy as np
import matplotlib.pyplot as plt from matplotlib.ticker import (MultipleLocator, AutoMinorLocator, FuncFormatter) import seaborn as sns import numpy as np
위 예제는 문자열을 담은 변수에 인덱싱을 한 것이다 첫번째 줄은 인덱스’2’의 문자를 가져오는 것인데 인덱스는 0부터 시작하므로 (2번째가아닌)3번째인’l’을 출력한것이다. 두번째 줄은 인덱스’6’부터 ‘9’까지(두번째인덱스-1)의 숫자를 가져오는 것이므로 ‘worl’이 출력되었다. 세번째 줄은 인덱스’2’부터 ‘10’까지를 가져오되, 한칸씩 건너뛰고(세번째 숫자가 3이므로) 가져오는것이다.
리스트(list)
접기 / 펼치기
리스트는 여러개의 문자열, 변수, 숫자 등을 담을수 있는 자료구조이다. 리스트의 장점은 다음과 같다.
인덱스 번호로 빠른 접근이 가능하다.
데이터의 위치에 대해 직접적인 접근(Access)가 가능하다.
1
fruit = [['apple', 'banana', 'cherry'], 123]
위가 리스트의 형태이다. 리스트의 값은 기본적으로 인덱스가 배정된다 이때는
1
print(fruit[0])
Output: [‘apple’, ‘banana’, ‘cherry’] 위와 같은 형태로 나타낼 수 있으며 해당 인덱스의 요소가 리스트라면 리스트 전체를 출력한다.
만약 위처럼 리스트가 중첩된 형태라면
1
print(fruit[0][1])
Output:
banana
위처럼 출력이 가능하며 이때 리스트의 요소중 해당 인덱스의 요소가 출력된다. 물론 이 때도 출력된 문자열에서 다음과 같이 문자열의 요소를 출력하는것도 가능하다.
1
print(fruit[0][1][3])
Output:
a
위와같이 결과가 출력된다.
리스트값 수정, 추가, 삭제하기
접기 / 펼치기
리스트가 여러 요소들의 집합이다보니 리스트의 값에 변동이 필요할 때가 있다. 리스트는 값의 수정, 추가, 삭제가 가능하므로 기능과 문법에 대해 알아둘 필요가 있다.
리스트 값 수정하기
1 2 3
a = [0,1,2] a[1] = "b" print(a)
Output:
[0, 'b', 2]
별다른 문법없이 리스트의 인덱스에 값을 넣어주니 수정이 되는것을 알 수 있다.
리스트 값 추가하기
append
1 2 3 4 5 6 7
a = [100, 200, 300] a.append(400) print(a)
b = [500,600] a.append(b) print(a)
Output:
[100, 200, 300, 400] [100, 200, 300, 400, [500, 600]] 리스트명.append(값)을 통해서 리스트에 값을 추가할 수 있으며 한개의 값만 추가할 수 있다. 리스트의 경우엔 한가지 값이며 추가할 경우 중첩된 리스트의 형태로 추가가 된다.
extend
extend는 append와 거의 같지만 다른점이 하나 있습니다. append는 인자(리스트, 튜플 등)를 주어도 인자 그대로를 리스트에 추가하지만, extend는 인자를 줄 경우 인자의 값 하나하나를 리스트에 추가한다.
1 2 3 4
a = [2, 9, 3] b = [1, 2, 3] a.extend(b) print(a)
Output:
[2, 9, 3, 1, 2, 3] 결과와 같이 append와 비교했을때 extend된 인자의 값 하나하나가 추가된걸 볼 수 있다.
insert
insert는 입력해준 위치의 인덱스에 값을 추가해준다.
1 2 3 4
a = [1,2,3] print(a) a.insert(1,'abc') print(a)
Output:
[1,2,3] [1,’abc’,2,3]
리스트 값 삭제하기
remove
1 2 3 4 5 6 7
a =[1,2,1,2] #리스트의 첫번째 1이 삭제 a.remove(1) print(a) #리스트의 두번째 였던 1이 삭제 a.remove(3) print(a)
Output:
[2, 1, 2] [2, 2] 리스트명.remove()는 괄호내의 값을 삭제한다. 만약 값이 리스트내에서 중복될경우 가장 앞에 있는 값을 삭제한다.
del
1 2 3 4 5 6 7 8 9 10
a = [0,1,2,3,4,5,6,7,8,9]
# 1 삭제 del a[1] print(a)
b = [0,1,2,3,4,5,6,7,8,9] # 범위로 삭제 del b[1:3] #list는 항상 시작하는 index부터, 종료하는 n의 n-1까지의 범위를 잡아준다. print(b)
Output:
[0, 2, 3, 4, 5, 6, 7, 8, 9] [0, 3, 4, 5, 6, 7, 8, 9] del 리스트명[인덱스]는 리스트의 인덱스에 위치한 값을 삭제해준다. 인덱스값에 범위를 주고싶다면 0:4 처럼 넣을수 있으며 이때는 0에서 3번째 값까지 삭제가 된다.
pop
1 2 3 4 5
a = [0,1,2,3,4] r = a.pop(1)
print(a) print(r)
Output:
[0, 2, 3, 4] 1 리스트명.pop()은 괄호내의 값을 해당 리스트에서 끄집어낸다.
튜플(tuple)
접기 / 펼치기
튜플은 리스트와 비슷하게 여러개의 문자열, 변수, 숫자 등을 담을수 있는 자료구조이다. 튜플과 리스트의 가장 차이점으로는 튜플은 값에대한 수정이 불가하다는 점이다. 그렇다면 튜플은 무슨 장점이 있느냐 라고 반문할 수 있는데 리스트와 비교한 튜플의 장점은 다음과 같다.
메모리 사용량이 적다.
생성 시간이 빠르다.
인덱스를 사용하여 튜플의 데이터에 접근하는 시간이 비교적 짧다.
튜플의 문법, 기본형태는 다음과 같다.
1 2 3 4 5 6 7 8 9 10 11
tuple1 = (0) # 끝에 콤마(,)를 붙이지 않았을 때 tuple2 = (0,) # 끝에 콤마(,)를 붙여줬을 때 tuple3 = 0,1,2
파이썬에도 집합연산이 있고, 자료구조들의 합,교,차집합에 대한 연산을 할수 있다. 기호는 |,&,-이며, 각각의 예시는 다음과 같다.
1 2 3 4 5
a = {1,2,3,4} b = {3,4,5,6} print(a|b) print(a&b) print(a-b)
Output:
{1, 2, 3, 4, 5, 6}
{3, 4}
{1, 2}
if 조건문
접기 / 펼치기
조건문이란 작성자가 명시한 조건식의 결과인 boolean값이 참인지 거짓인지에 따라 달라지는 계산이나 상황을 수행하는 문장이다.
1 2 3 4 5 6 7 8 9 10
a = -5
if a>5: print('a는 5이상입니다')
elif a > 0: print("a는 0초과, 5이하입니다")
else: print("a는 음수입니다")
Output:
a는 음수입니다.
조건식에는 기본적으로 조건식이 들어가지만 True나 False등의 직접적인 bool형 변수가 삽입될수도 있으며, and,or 등과 결합하여 여러가지의 조건식을 사용할수도 있다.
반복문 (for,while)
접기 / 펼치기
같은동작을 여러번 반복해야 할 때 같은코드를 여러번 적어넣는건 비효율적이다. 그럴때 반복문을 사용하면 훨씬 적은양의 코드로도 같은효과를 낼 수 있다.
for문
for문의 기본 구조
1 2 3
for 변수 in 리스트(또는 튜플, 문자열) : 수행할 문장1 수행할 문장2
리스트나 튜플, 문자열의 첫 번째 요소부터 마지막 요소까지 차례로 변수에 대입되어 “수행할 문장1”, “수행할 문장2” 등이 수행된다.
1 2 3
a = ['1','2','3'] for i in a : print(i)
Output: 1 2 3
리스트 a의 첫번째 값인 1이 i에 대입되고 print(i)가 출력된다. 다음엔 두번째 값인 2가 대입되고 출력된다. 이것을 마지막 값까지 반복한다.
while문
while문의 기본 구조
1 2 3 4 5
while <조건문>: <수행할 문장1> <수행할 문장2> <수행할 문장3> ...
while문은 for보다는 간단하다. while, 조건문, 실행문 이 세개면 완성되기 때문이다. 이러한 특성때문에 while문은 조건문을 거짓으로 만들어주는 문장이 없다면 무한실행된다. 프로그램 뻗는다 간단한 예제를 보면 다음과 같다.
1 2 3 4
i = 0 while i <= 5 : print("{}번째 반복입니다.".format(i)) i += 1
Output: 0번째 반복입니다. 1번째 반복입니다. 2번째 반복입니다. 3번째 반복입니다. 4번째 반복입니다. 5번째 반복입니다. 변수 i로 인해 자동으로 조건식이 False가 되면서 while문이 종료되는 모습이다. 이렇듯 while문은 조건문을 거짓으로 만들어주는 무엇인가가 없다면 종료되지않는다.