파이썬(Python) 데이터 크롤링 기초 수업 정리
개발자나 데이터분석가에게 중요한 능력중 하나를 꼽자면 무엇일까.
자신이 진행할 프로젝트의 데이터를 수집하는 능력도 꽤나 중요하지 않을까 싶다.
그러기 위해서는 크롤링을 해야 할 때가 있는데 크롤링이란 HTML(웹페이지)를 그대로 가져와 데이터를 추출하는 행위를 말한다.
그래서 이번 포스트에서는 학원에서 배운 간단한 크롤링에대해 수업 그대로를 정리하려 한다.
사전준비
크롤링을 하기위해 일단 BeautifulSoup 라는 파이썬 라이브러리를 설치해 주어야 한다.
다음 코드를 터미널에 입력해 라이브러리를 설치한다.
1 | pip install beautifulsoup4 |
설치가 완료되었다면 예제 HTML 문서를 하나 만들어주면 준비는 끝난다.
index.html
1 |
|
BeautifulSoup를 사용하여 크롤링
먼저 크롤링을 하기 위해 파이썬 파일을 만들어준다.
1 | from bs4 import Beautifulsoup |
이후 Beautifulsoup 라이브러리를 import하고 간단한 함수를 만들어 크롤링을 해보자.
HTML 불러오기
1 | def crawling(): |
1 | <!DOCTYPE html> |
HTML 파일이 soup에 저장되어 출력된 것을 볼 수 있다.
필요한 태그만 가져오기
하지만 우리는 HTML 전체가 아닌 특정 텍스트, 태그만 필요로 하기 때문에 그것들을 뽑아낼 수 있어야 한다.
1 | def crawling(): |
1 | <p>Don't crawl this.</p> |
find()함수는 가장 앞쪽의 한 태그만을 가져온다.
이처럼 p태그가 출력되었는데 두가지 의문이 생길 것이다.
‘p태그는 두개인데 왜 한개만 출력되는가?’와 ‘<p></p>없이 텍스트만 추출 할수 없는가?’라는 것이다.
물론 가능하다.
첫번째는 find()함수를 find_all()로 바꾸면 모든 p태그가 출력되고,
두번째는 find()함수 뒤에 .get_text()를 붙여주면 태그가 제외된 텍스트만 출력이 된다.
이외에도 많은 함수가 있고, Beautiful Soup Documentation 에서 찾아볼 수 있다.
class, id로 태그 가져오기
여전히 크롤링이라기엔(기초지만) 부족하다 원하는 태그를 가져올 수는 있으나 태그가 여러개면 같이 가져올 수밖에 없기 때문이다.
그래서 이번에는 각 태그에 주어진 class와 id를 통해 크롤링하는 법에 대해 알아보자.
index.html을 보면 div태그에 각각 class와 id가 있다.
이를통해 크롤링 하는 코드를 보면
1 | def crawling(): |
다음과 같으며 이를 실행하면
1 | Hello, Python Crawling! |
위와 같이 출력된다.
만약 class가 아닌 id를 지정해서 태그를 찾고싶을 경우 find()함수 내에 class_ = 가 아닌 id = 를 입력하면 된다.
class는 언더바가 붙고 id는 붙지 않는다.
OPEN API를 통해 데이터 가져오기
open API를 통해 데이터를 가져오는 법도 간단히 알아보자.
이 포스팅은 캐글을 기반으로 진행했으며 데이터는 한국도로공사 공공데이터 포털 의 교통데이터를 이용했다.
먼저 API에 접근하기 위해 인증키를 발급 받는다.
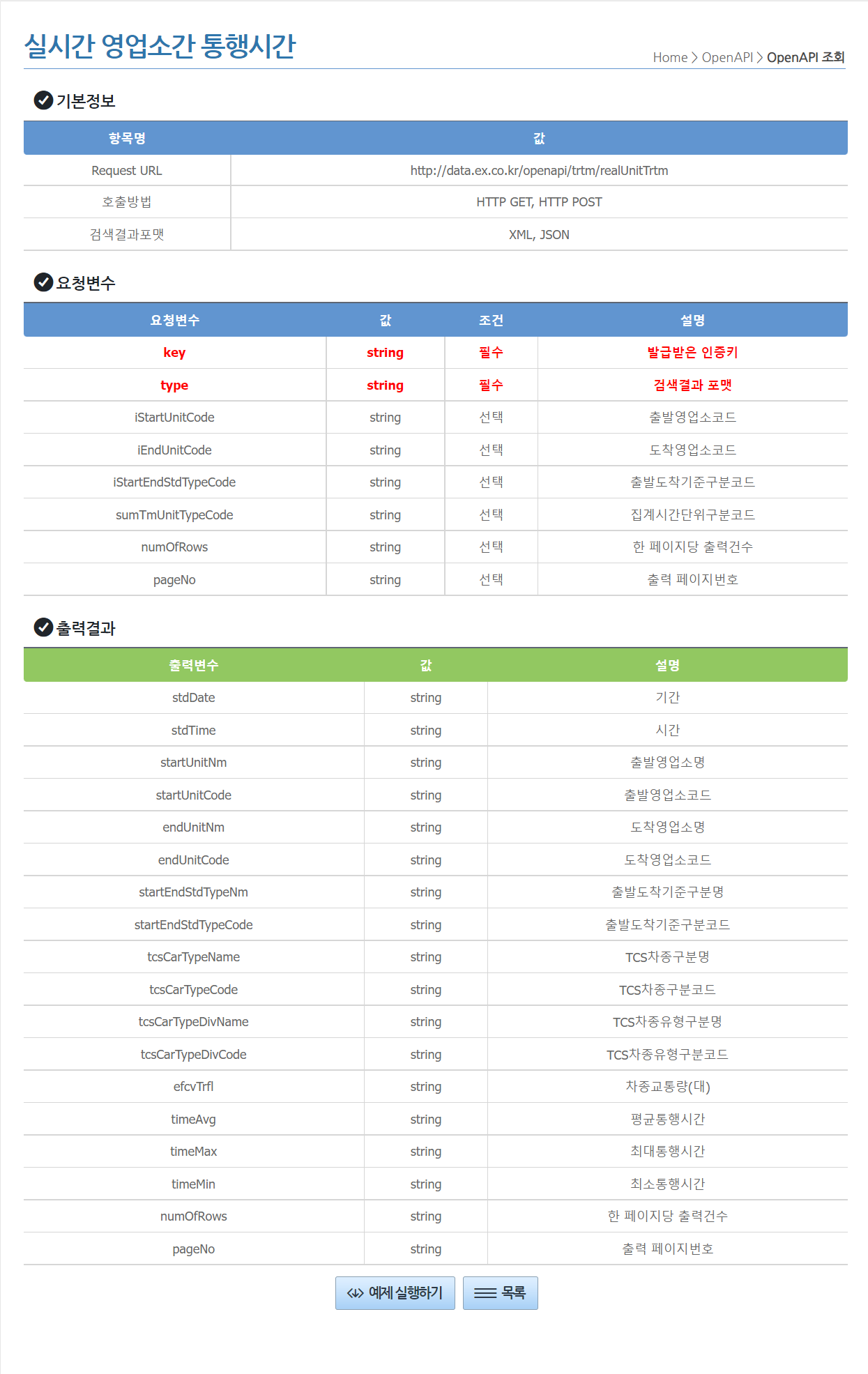
이후 실시간 영업소간 통행시간 페이지 에 접속해 아래의 예제 실행하기를 클릭.
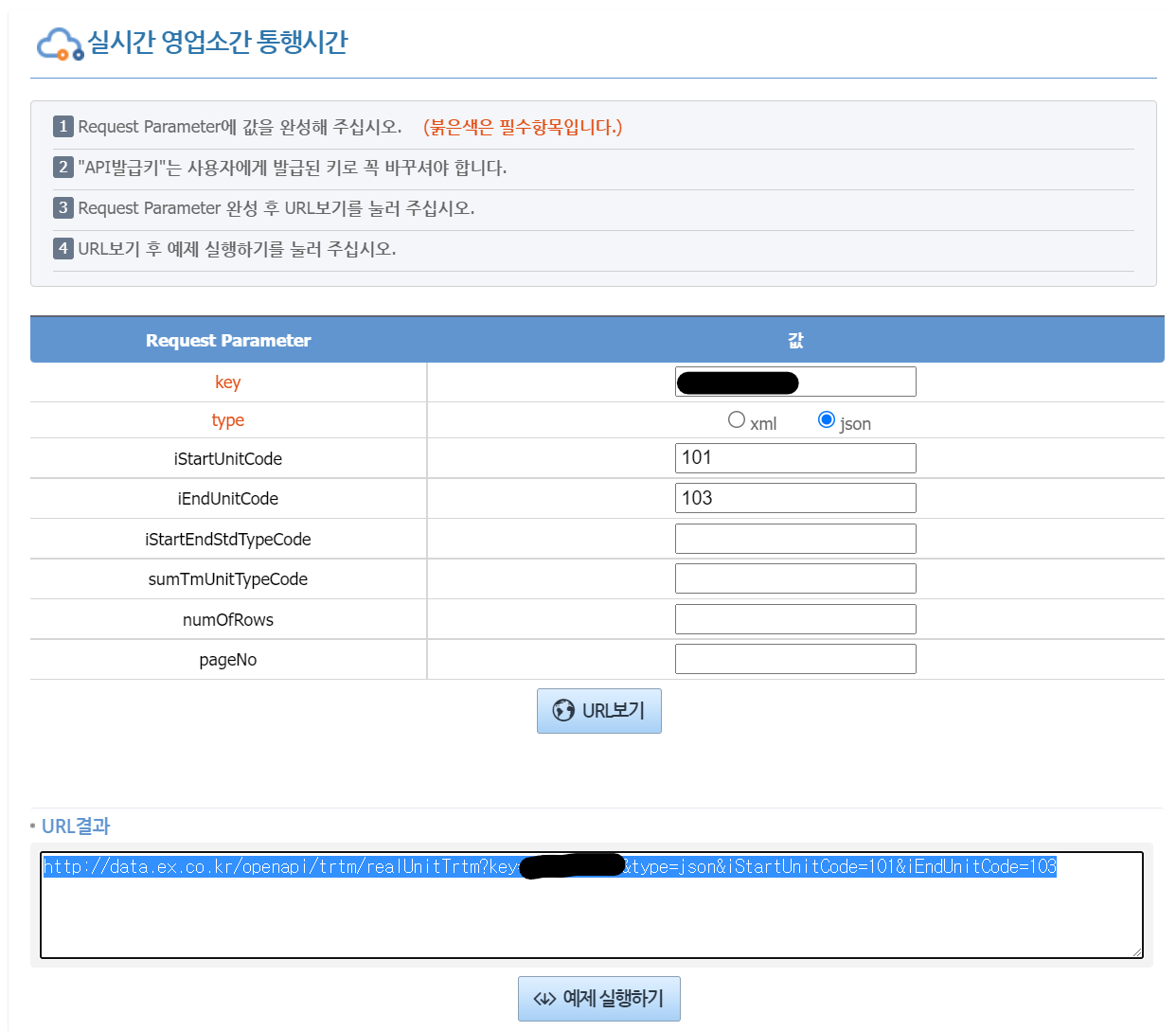
원하는 Request Parameter를 입력하고(필자는 key(여기서 키는 방금 발급받은 인증키), type, iStartUnitCode, iEndUnitCode만 작성) URL보기를 하면 URL이 출력되고 , 아래의 예제 실행하기를 통해 직접 볼 수도 있다.
이제, 캐글에 다음과 같이 입력해준다.
1 | import requests |
을 입력해주면
팝업에서 보았던 예제를 직접 볼 수 있다.
필요한 정보가 있는 “realUnitTrtmVO” 항목을 가져오기 위해 다음 코드 입력
1 | cars = json["realUnitTrtmVO"] |
이것을 반복문을 통해 리스트, 딕셔너리 형태로 만들어준다.
1 | data = [] |
아래는 아웃풋
1 | [{'date': '20220103', 'destination': '수원신갈', 'time': '05:30'}, |
이렇게 딕셔너리로 구성된 리스트가 생성되었다.
이것을 Pandas Dataframe으로 변환후 엑셀시트로 출력하려면 다음과 같이 하면 된다.
1 | import pandas as pd |
이렇게하면 설정된 곳으로 캐글에서 데이터프레임이 다운로드된다.