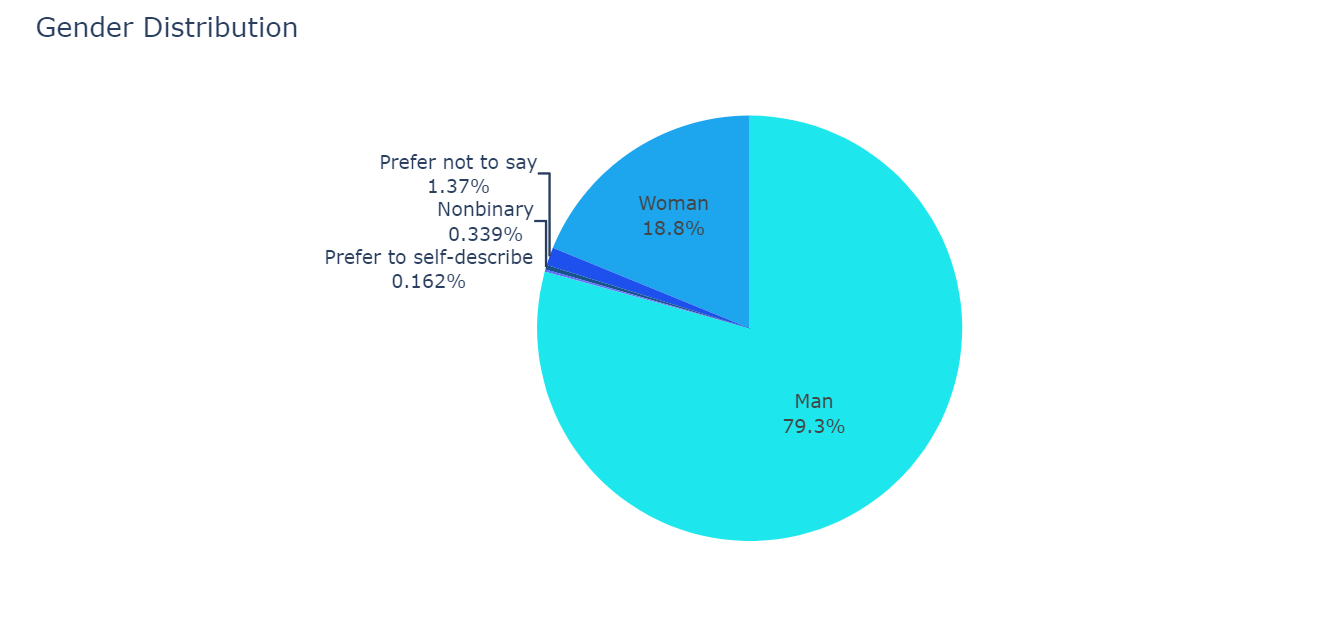
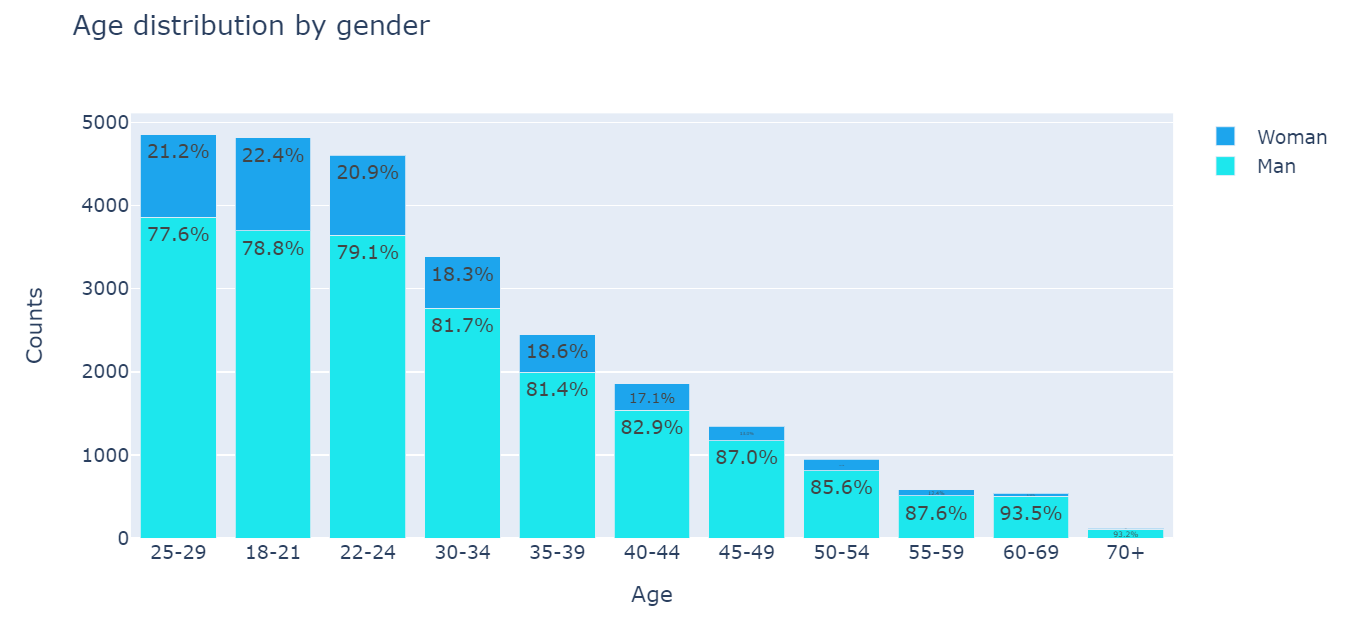
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| df19_JP = df19[df19.Q3.isin(['Japan'])]
df19_CN = df19[df19.Q3.isin(['China'])]
df21_JP = df21[df21.Q3.isin(['Japan'])]
df21_CN = df21[df21.Q3.isin(['China'])]
df19_JP_Q14 = pd.DataFrame()
df19_CN_Q14 = pd.DataFrame()
df21_JP_Q14 = pd.DataFrame()
df21_CN_Q14 = pd.DataFrame()
df19_JP_Q14['Q20'] = [df19_JP[col][1:].value_counts().index[0] for col in df19_JP.columns[97:109]]
df19_CN_Q14['Q20'] = [df19_CN[col][1:].value_counts().index[0] for col in df19_CN.columns[97:109]]
df21_JP_Q14['Q14'] = [df21_JP[col][1:].value_counts().index[0] for col in df21_JP.columns[59:71]]
df21_CN_Q14['Q14'] = [df21_CN[col][1:].value_counts().index[0] for col in df21_CN.columns[59:71]]
df19_JP_Q14['counts'] = [df19_JP[col][1:].value_counts().values[0] for col in df19_JP.columns[97:109]]
df19_CN_Q14['counts'] = [df19_CN[col][1:].value_counts().values[0] for col in df19_CN.columns[97:109]]
df21_JP_Q14['counts'] = [df21_JP[col][1:].value_counts().values[0] for col in df21_JP.columns[59:71]]
df21_CN_Q14['counts'] = [df21_CN[col][1:].value_counts().values[0] for col in df21_CN.columns[59:71]]
df19_JP_Q14.index = [3,0,6,4,5,2,7,1,8,9,10,11]
df19_CN_Q14.index = [3,0,6,4,5,2,7,1,8,9,10,11]
df19_JP_Q14 = df19_JP_Q14.sort_index()
df19_CN_Q14 = df19_CN_Q14.sort_index()
df21_JP_Q14['Q14'].index = [0,1,2,3,4,5,6,7,8,9,10,11]
df21_CN_Q14['Q14'].index = [0,1,2,3,4,5,6,7,8,9,10,11]
df19_JP_Q14.replace(regex = 'D3.js', value = 'D3 js', inplace = True)
df19_CN_Q14.replace(regex = 'D3.js', value = 'D3 js', inplace = True)
fig_T = make_subplots(rows=1, cols=2, specs=[[{'type':'xy'}, {'type':'xy'}]])
fig_T.add_trace(go.Bar(name=coun_years[0], x=df19_JP_Q14['Q20'].values, y=df19_JP_Q14['counts'], marker_color=coun_years_colors[0]),1,1)
fig_T.add_trace(go.Bar(name=coun_years[1], x=df19_CN_Q14['Q20'].values, y=df19_CN_Q14['counts'], marker_color=coun_years_colors[1]),1,1)
fig_T.add_trace(go.Bar(name=coun_years[2], x=df21_JP_Q14['Q14'].values, y=df21_JP_Q14['counts'], marker_color=coun_years_colors[2]),1,2)
fig_T.add_trace(go.Bar(name=coun_years[3], x=df21_CN_Q14['Q14'].values, y=df21_CN_Q14['counts'], marker_color=coun_years_colors[3]),1,2)
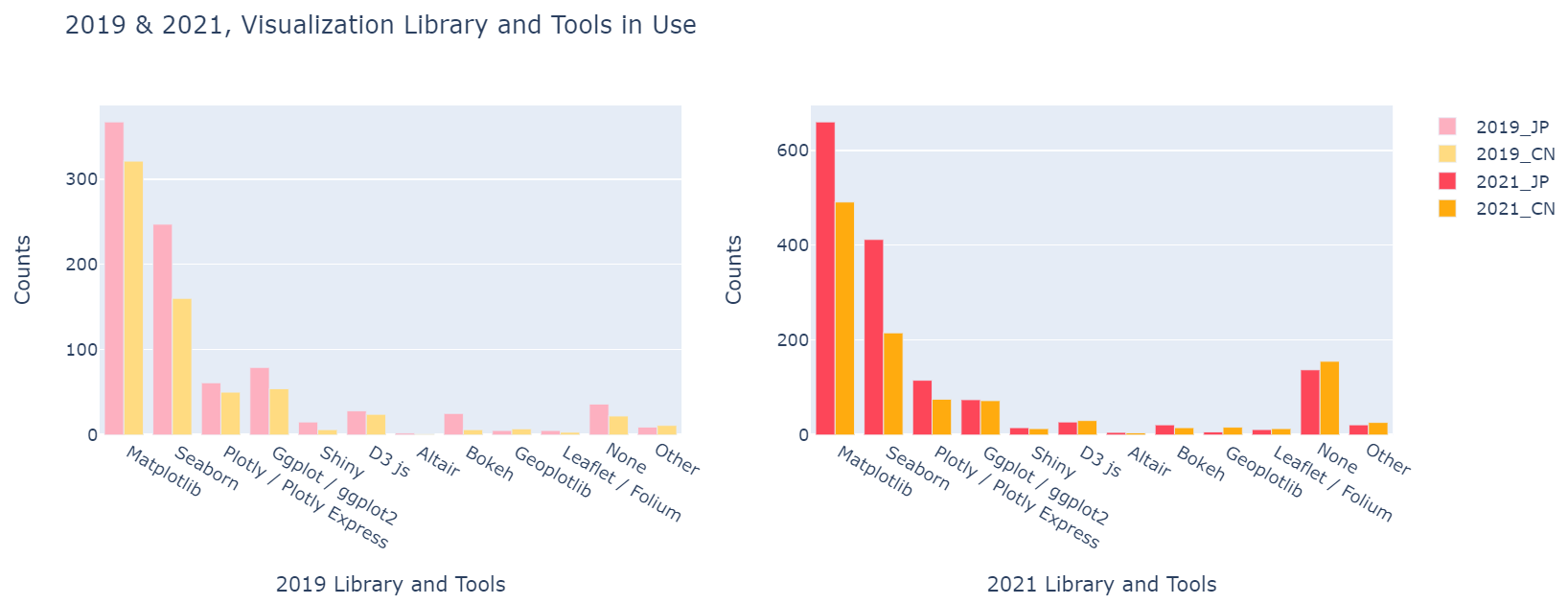
fig_T.update_layout(title_text='2019 & 2021, Visualization Library and Tools in Use',
showlegend=True,
autosize=True)
fig_T.update_xaxes(title_text='2019 Library and Tools', row=1, col=1)
fig_T.update_yaxes(title_test='Counts', row=1, col=1)
fig_T.update_xaxes(title_text='2021 Library and Tools', row=1, col=2)
fig_T.update_yaxes(title_text='Counts', row=1, col=2)
fig_T.show()
|