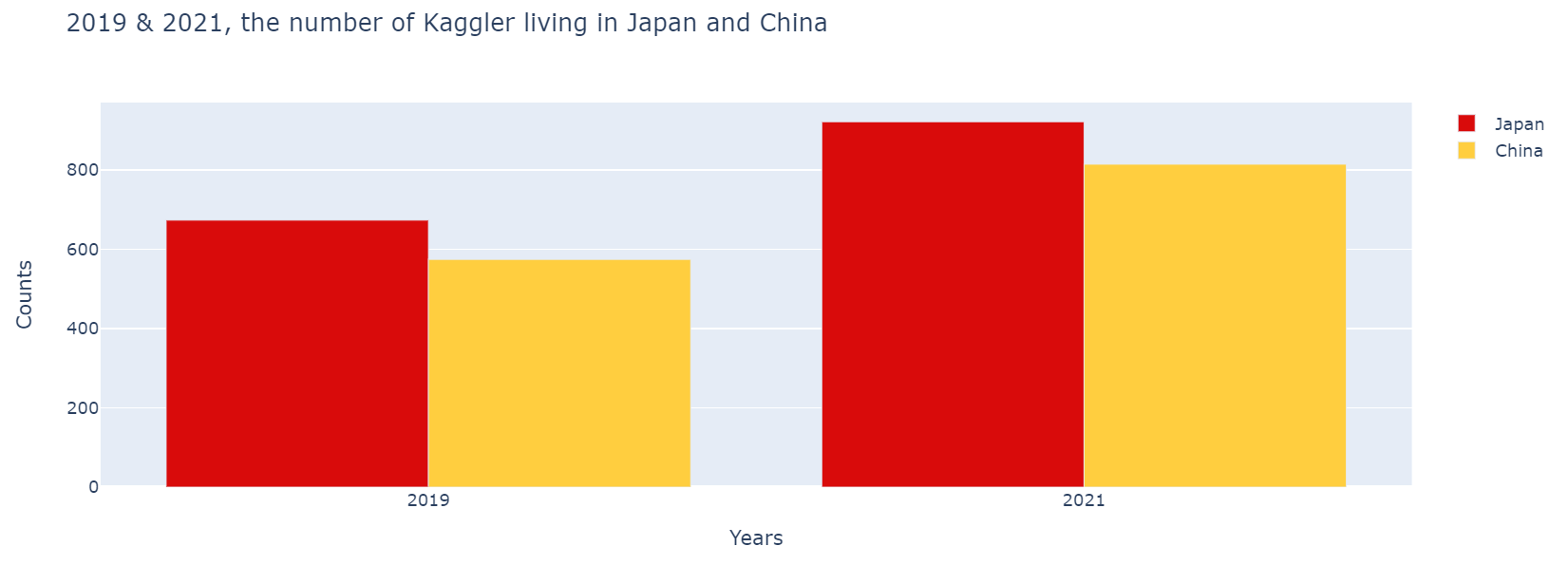
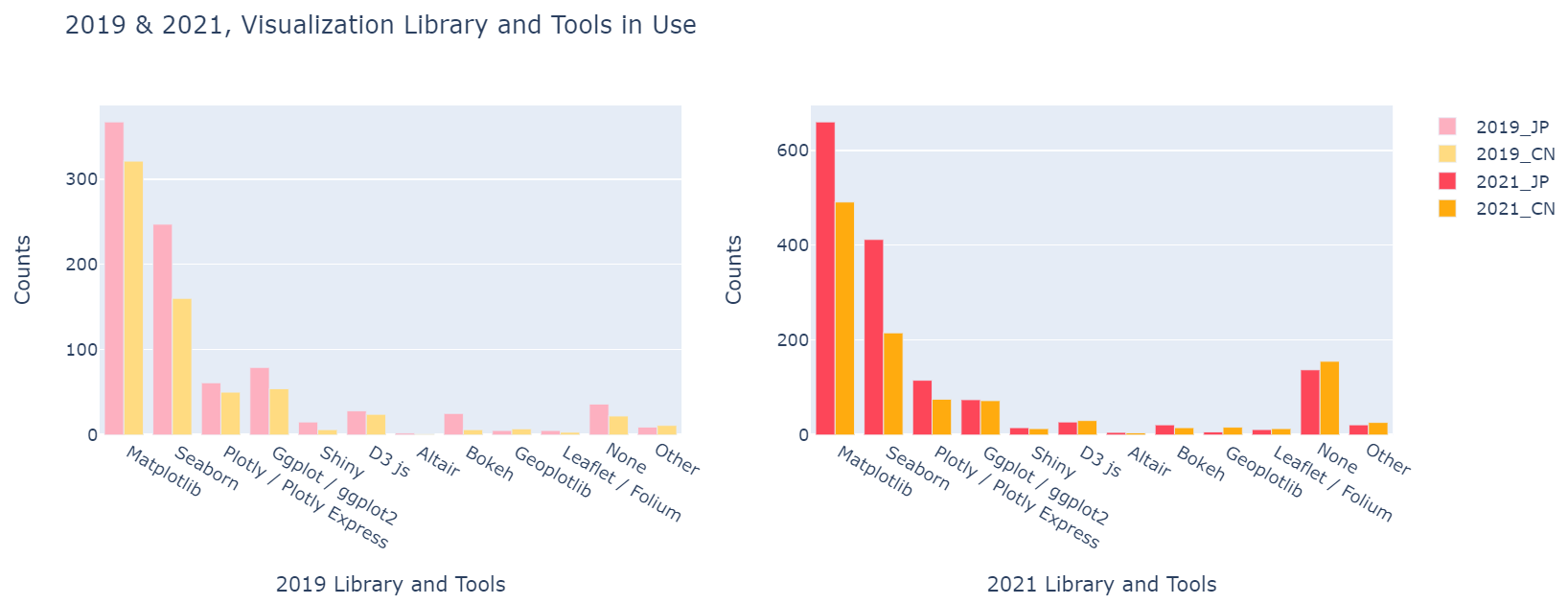
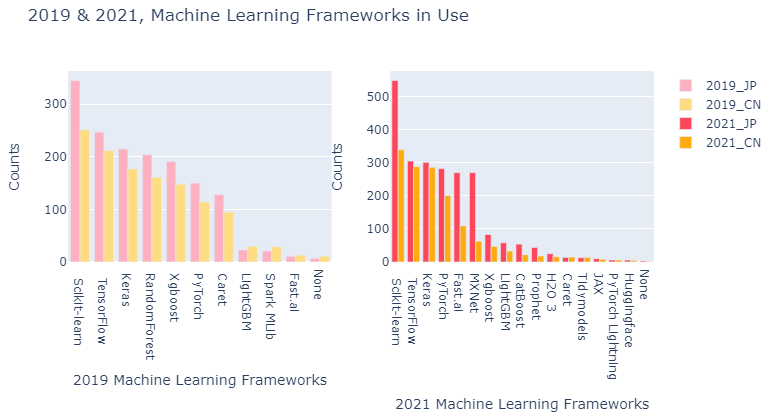
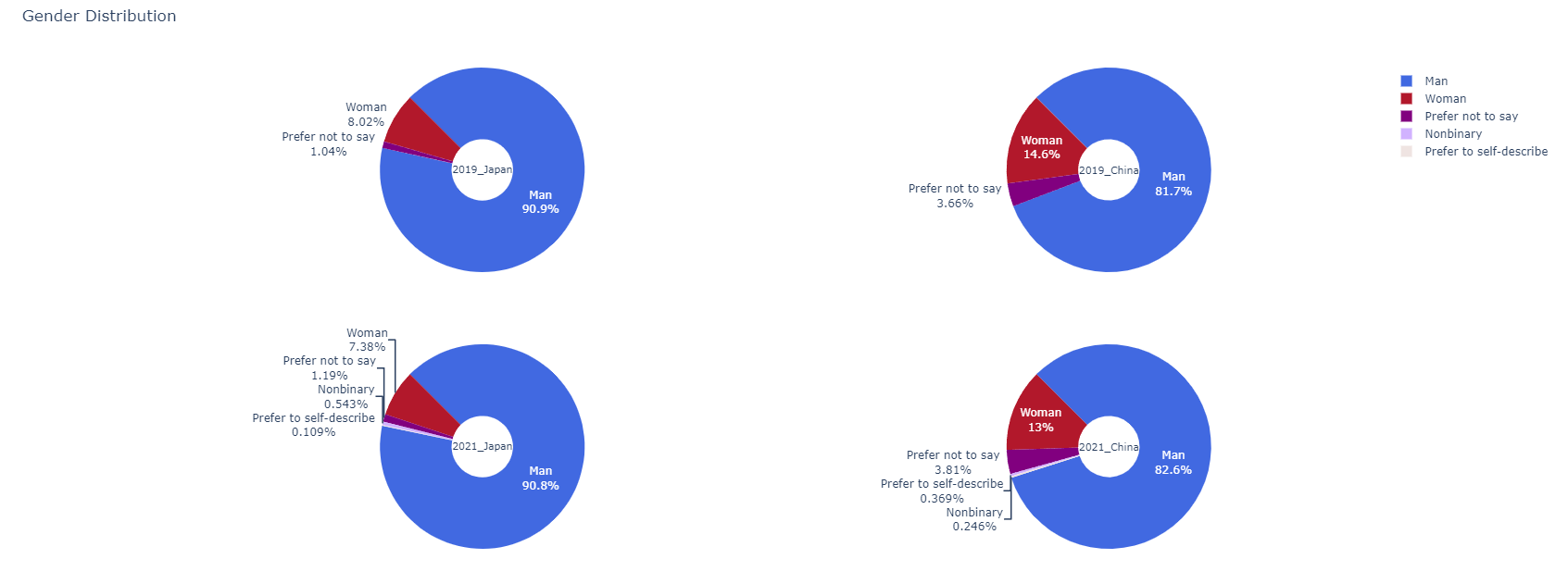
plotly를 사용하여 막대그래프 만들기
캐글 대회에 참가하면서 파이썬 문법이나 plotly의 특성에 대해 구글링하는 시간이 훨씬 늘었다.
앞으로도 대회에 참가하거나 시각화를 할 때에 이렇게나 많은 특성을 모두 외울수는 없으니 구글링을 하게 될 텐데, 자주쓰는 속성이나 기본틀에 대해서는 포스팅을 해두고 바로바로 찾아보는것이 좋겠다는 생각이 들었다.
그래서 이번 포스팅에서는 앞으로 자주 사용하게 될 차트 중 하나인 막대그래프의 기본 틀과 자주 사용되는 속성에 대해 포스팅 하려 한다.
데이터는 2021 Kaggle Machine Learning & Data Science Survey 대회의 데이터를 사용한다.
import 및 데이터 불러오기
1 | import plotly.graph_objects as go |
필요한 라이브러리를 import 해주고 데이터를 불러와 저장해준다.
필자는 캐글노트북에서 작성하여 data add 기능으로 kaggle에 있는 데이터를 바로 불러왔지만 로컬이나 colab, jupyter등의 다른 노트북을 사용중이라면 데이터를 다운받은후 괄호안의 경로를 재설정해주어야 한다.
출력할 데이터 확인
1 | df21[0:5][Q1,Q14] # Q1,Q14 항목의 값 0부터 4까지 출력 |
| ㅤ | Q1 | Q3 |
|---|---|---|
| 0 | What is your age (# years)? | In which country do you currently reside? |
| 1 | 50-54 | India |
| 2 | 50-54 | Indonesia |
| 3 | 22-24 | Pakistan |
| 4 | 45-49 | Mexico |
이렇게 출력하거나
1 | df21[df21['Q3'] == "South Korea"] # Q3 항목의 값이 "South Korea"인 행의 데이터프레임 출력 |
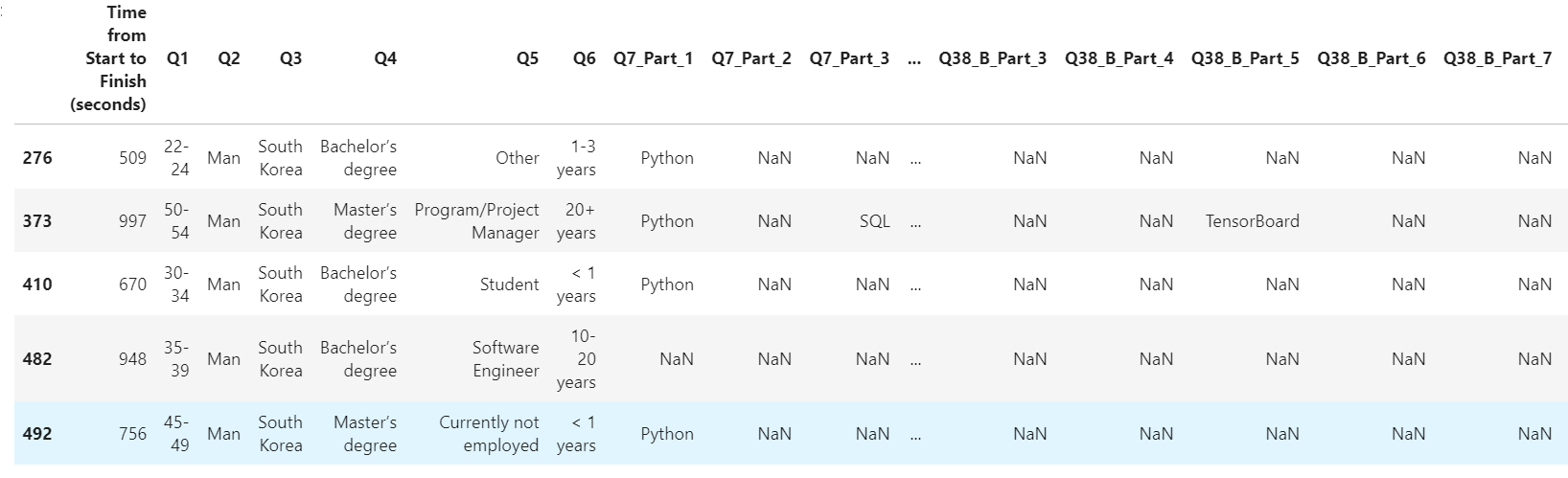
위 코드처럼 어느 조건에 해당하는행을 출력 할 수도 있다.
1 | KR_Age = df21[df21['Q3'] == 'South Korea']['Q1'].value_counts() |
위 코드는 Q3(국가)이 South Korea인 행과 Japan인 행의 Q1(연령)값을 뽑아내는 코드로 이를 통해 그래프를 만들어 볼 것이다.
다중 차트 틀 만들기
위에서 import한 make_subplots으로 차트여러개를 출력 할 수 있다.
1 | fig = make_subplots(rows=1, cols=2, specs=[[{'type':'xy'}, {'type':'xy'}]]) |
fig 객체를 생성해주고 차트를 1행, 2열로 만들어주는 코드이다.
막대그래프의 경우엔 'type':'xy' 파이그래프의 경우엔 'type':'domain'으로 할수있다.specs에서 중괄호는 차트한개를 나타내며 내부의 중괄호가 여러개라면 각각 행을 구분하는 용도로 쓰인다.
각 속성으로 차트 그리기
1 | fig.add_trace(go.Bar(name='Korea', x=KR_Age.index, y=KR_Age.values, marker_color='red'),1,1) |
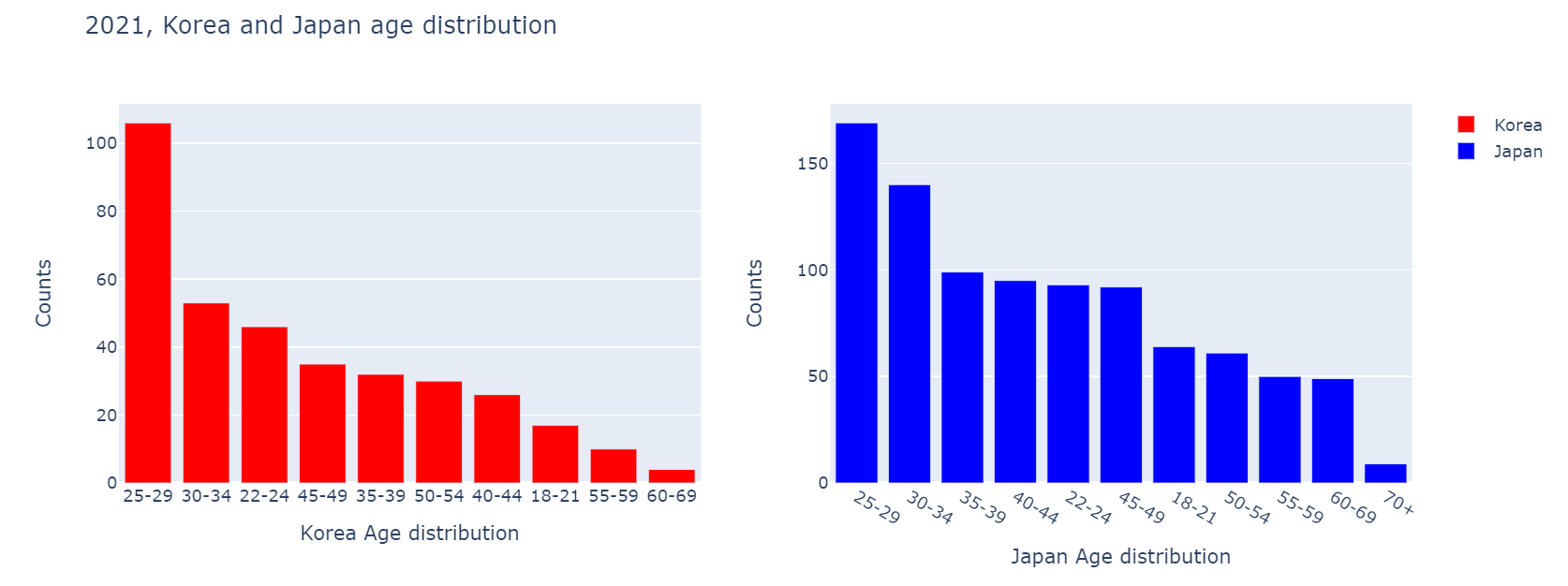
add_trace, update_layout 등의 파라미터(속성)값으로 그래프를 꾸미는 코드이다.
fig.add_trace(go.Bar(name='Korea', x=KR_Age.index, y=KR_Age.values, marker_color='red'),1,1)부터 살펴보면go.Bar는 막대그래프를 뜻한다, 각 파라미터를 살펴보면name는 그래프에 표현되는 항목의 이름,x는 그래프의 x축이 나타낼 항목,y는 그래프의 y축이 나타낼 값,marker_color은 그래프의 색을 표현하며
가장 끝의1,1는 위 항목이 표시될 그래프의 행,열을 뜻한다.(그러니 1번째 행 1번째 열의 그래프에 Korea 항목이 들어간다.)
fig.update_layout(barmode='group', title_text='2021, Korea and Japan age distribution', showlegend=True)도 뜯어보겠다.barmode는 한 그래프에 여러 항목이 들어있을 경우 어떻게 나타내는지에 대한 속성인데 대표적으로 group과stack이 있다.title_text는 제목, showlegend는 범례 표기 여부를 가리킨다.
마지막의 fig.show()는 fig객체를 출력하는 코드이다.
아래 References에 막대그래프의 파라미터가 정리되있는 링크를 걸어놓을테니 활용하여 다양하게 그래프를 만들어보자.